
De la restitution des descriptions archivistiques
Les archivistes décrivent des ressources archivistiques afin de faciliter, pour leurs publics, l’accès aux informations contenues dans ces ressources.Ils décrivent des ressources qui, généralement, constituent des ensembles cohérents, par exemple un fonds.
Avant l’arrivée de l’informatique, ces descriptions ont pu être disponibles sous forme de fiches présentes, par exemple, dans des tiroirs, ou sous forme de documents (manuscrits, dactylographiés, imprimés) nommés instruments de recherche. Dans ces derniers, les descriptions sont organisées d’une manière plus ou moins hiérarchique qui doit refléter l’organisation du fonds, qui, lui-même, est supposé refléter l’organisation de la personne (physique ou morale) qui l’a produit.
Avec l’arrivée de l’informatique dans les archives, Les choses ont progressivement évolué.
- La diffusion des logiciels de traitement de texte, dans les années 1980, a permis de réaliser des instruments de recherche bien présentés, sans avoir nécessairement recours à un professionnel comme l’imprimeur.
- Avec la diffusion de l’informatique documentaire, dans les années 1980 et 1990, les logiciels documentaires ont permis des recherches dans les descriptions archivistiques, beaucoup plus efficaces que les tiroirs à fiches. Simplement, ces logiciels ne permettaient pas de rendre compte de l’organisation hiérarchique. Ils contraignaient donc à renoncer au principe de description à plusieurs niveaux. Les services d’archives les plus en pointe réalisaient un double travail, en produisant d’une part des instruments de recherche hiérarchisés à l’aide de logiciels de traitement de texte et, d’autre part, des bases de données documentaires à plat.
- C’est à cette époque, au début des années 1990, qu’Anaphore a entrepris une synthèse de ces deux modes en développant, à partir de 1991, le module Arkhéïa Aide au classement. Celui-ci permettait, depuis l’origine, de saisir des notices descriptives des ressources archivistiques, de les organiser hiérarchiquement et de les restituer sous forme d’instruments de recherche hiérarchisés et de bases de données à plat exploitables par différents logiciels documentaires.
- En 1994, est arrivée la première version de la nome ISAD(G) qui réaffirmait le principe de description à plusieurs niveaux. Cette norme n’a pas été immédiatement mise en œuvre en France, faute, en particulier, d’outil à cet effet. En 1998 Arkhéïa Aide au classement a intégré cette norme.
- D’une façon générale, en dehors des utilisateurs d’Arkhéïa, le principe de description à plusieurs niveaux a été un peu délaissé au cours des années 1990.
- En 1999, l’ouvrage de Christine Nougaret et Bruno Galland Les instruments de recherche dans les archives a remis à l’honneur ce principe et a, d’une certaine façon, marqué un retour aux fondamentaux de l’archivistique.
- Au tout début des années 2000, le format XML a commencé à se répandre et, là encore, Anaphore l’a intégré dans son outil, permettant des restitutions des instruments de recherche en XML, pas encore EAD. Anaphore a alors initié le développement de moteurs de recherche propre aux archives, c’est-à-dire prenant en compte la description à plusieurs niveaux, à partir de ces fichiers XML.
- En 2001-2002, est arrivée en France la DTD EAD. Anaphore l’a immédiatement intégrée dans son outil de production d’instruments de recherche et s’est rapproché de Martin Sévigny pour initier ce qui est devenu Pleade.
- Le format XML-EAD, à condition d’être utilisé de manière pertinente, c’est-à-dire en se préoccupant d’abord de la qualité des contenus et ensuite seulement de la syntaxe du format, a permis de produire des instruments de recherche vraiment structurés hiérarchiquement.
- Depuis le début de la décennie 2010, avec le mouvement vers le web des données, avec les réflexions et travaux sur des modèles conceptuels pour les archives, la question de l’organisation des descriptions archivistiques est de nouveau posée : après le modèle liste, puis le modèle arbre, faut-il évoluer vers un modèle plus riche ? En effet, le format XML a potentiellement permis une bien meilleure structuration hiérarchique des descriptions archivistiques. Mais, le modèle hiérarchique n’a-t-il pas aussi des limites qu’il faudrait maintenant dépasser ? Nous n’avons pas l’ambition de répondre à cette question, mais, peut-être, d’apporter quelques éléments au débat.
Schématiser différents modes d’organisation de descriptions archivistiques
A partir d’un exemple extrêmement simple, ce premier texte tente quelques réponses concrètes.
Un exemple simple
Nous avons tenté de traduire graphiquement les descriptions de petits fonds. Connaissant un peu ceux des archives de Vaucluse, nous avons choisi des exemples pris dans les fonds de couvents des Ursulines. Nous nous sommes intéressés d’abord aux Ursulines de Bollène, pour lesquelles un instrument de recherche est disponible.
Nous reproduisons ci-dessous la structure de cet instrument de recherche présent sur le site des archives de Vaucluse.
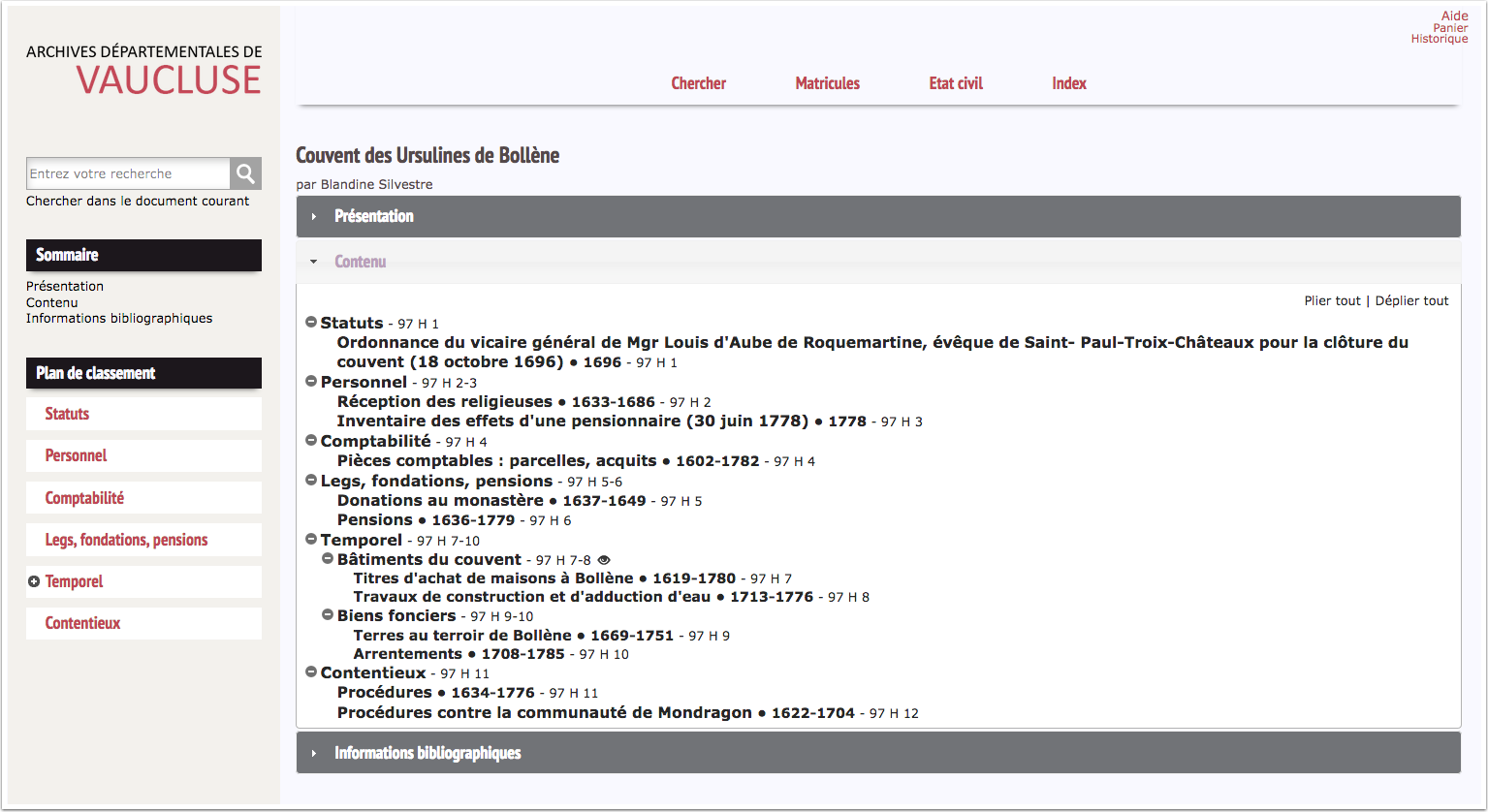
- Couvent des Ursulines de Bollène correspond au fonds.
- Ordonnances du vicaire…, Réception des religieuses, etc. aux articles.
Modèle en liste
Pour être utilisable dans une base de données documentaire « à plat », les descriptions doivent être structurées en conséquence. On renonce donc au principe de description à plusieurs niveaux et, par conséquent, à la non-redondance des informations entre les niveaux. On crée, au contraire de la redondance. On trouvera ci-dessous une représentation schématique. Bien entendu, chaque description est généralement composée de plusieurs rubriques, une pour la cote, une pour les dates, une pour l’intitulé…
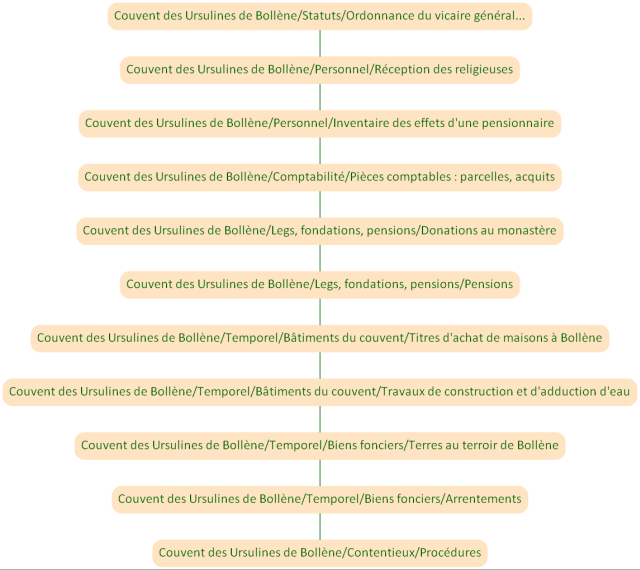
Ce mode d’organisation correspond à ce que l’on a, par exemple avec un tableur ou un gestionnaire de fichier simple : on a une organisation horizontale, chaque colonne correspondant à un type d’information, mais pas d’organisation verticale.
L’avantage d’une telle représentation est qu’elle est simple et, comme déjà dit, qu’elle est facilement exploitable par des logiciels documentaires.
Les inconvénients sont connus. En particulier, l’organisation hiérarchique n’est pas restituée, ni structurellement, ni visuellement. De ce fait, chaque description n'apparait pas dans son contexte.
Comme on l’a vu, la redondance d’informations descriptives pallie cette limite. Et, si celles-ci sont nombreuses, le modèle devient rapidement complexe.
Les restitutions ne permettent pas non plus de visualiser l’organisation.
Modèle en arbre

Le modèle hiérarchique peut être représenté de manière graphique. La structure est alors clairement visualisable. Bien entendu, dans le cas d’organisations complexes, il faut parcourir l’arbre, le déplier et le replier, agrandir des parties pour voir des détails et, au contraire, réduire pour avoir une vue globale…
Ici encore, chaque nœud de l’arbre peut être composé de plusieurs rubriques, par exemple, une pour la cote, une pour les dates…
Le modèle arbre permet de visualiser les relations entre les différentes composantes de la description, en tout cas les relations de type tout-partie.
Les limites du modèle hiérarchique et du langage XML
Beaucoup d’informations implicites
On a reproché, à juste titre, aux instruments de recherche réalisés avec un logiciel de traitement de texte de n’être hiérarchiques qu’en trompe-l’œil. La hiérarchie n’est que visuelle et non de réellement structurelle, ce qui explique une bonne partie des difficultés de rétro-conversion de ces instruments de recherche : leur organisation apparente ne correspond souvent pas à une structuration de fond.
Mais, même dans un fichier XML-EAD, beaucoup d’informations sont plus implicites qu’explicites.
- Par exemple, les relations hiérarchiques ne sont données que par l’emboitement de composants <c>, mais ne sont pas explicitement exprimées.
- Par exemple, l’ordre dans lequel doivent se succéder des composants « frères » (de mêmes parents) n’est donné que par les positions relatives de ces composants dans le fichier XML.
La nature implicite de ces informations ne pose pas vraiment de problème à la lecture humaine dans la mesure où l’œil et le cerveau humain reconstituent la hiérarchie et la séquence des descriptions. Mais, ces ambiguïtés peuvent poser problème pour des traitements automatiques et, par exemple, pour les moteurs de recherche.
Dans la vie, tout n’est pas hiérarchique
Même dans un instrument de recherche hiérarchique, de nombreuses propriétés ne sont pas de nature hiérarchique. Un fonds est en relation avec son producteur. Un fonds peut être en relation avec un autre fonds, un composant d’un fonds avec un autre composant du même fonds ou d’un autre fonds… Un composant avec une image qui l’illustre ou une image qui reproduit le document décrit…
On n'a pas toujours une racine
Le modèle arbre et le langage XML impliquent un point de départ unique que l’on appelle racine (root en anglais).
- Si l’on considère un fonds, on peut en effet définir une racine unique qui est le fonds lui-même.
- Mais, si l’on considère plusieurs fonds en relations, on a du mal à trouver une racine unique. Dans la pratique archivistique, on contourne ce problème d’une part en ne représentant pas toutes les relations qui peuvent exister entre différentes entités et, d’autre part, en élaborant des états des fonds, constructions intellectuelles, utiles mais artificielles, qui donnent une vue particulière, par exemple thématique, chronologique… de l’organisation des différents fonds.
Modèle graphe
Le modèle graphe permet des représentations plus riches que le modèle arbre en prenant en compte tout type de relation entre des entités de même nature ou des natures différentes. Le principe est simple et a déjà été exposé sur ce blog et ailleurs : on représente la relation entre deux entités et ainsi, de proche en proche, on construit un réseau qui peut être complexe. La nature des relations est, de plus, clairement explicitée et non simplement implicite comme dans le cas d’un fichier XML.
Dans la représentation ci-dessous, on retrouve les mêmes propriétés que dans la précédente, à la différence qu’elles ont été explicitées.
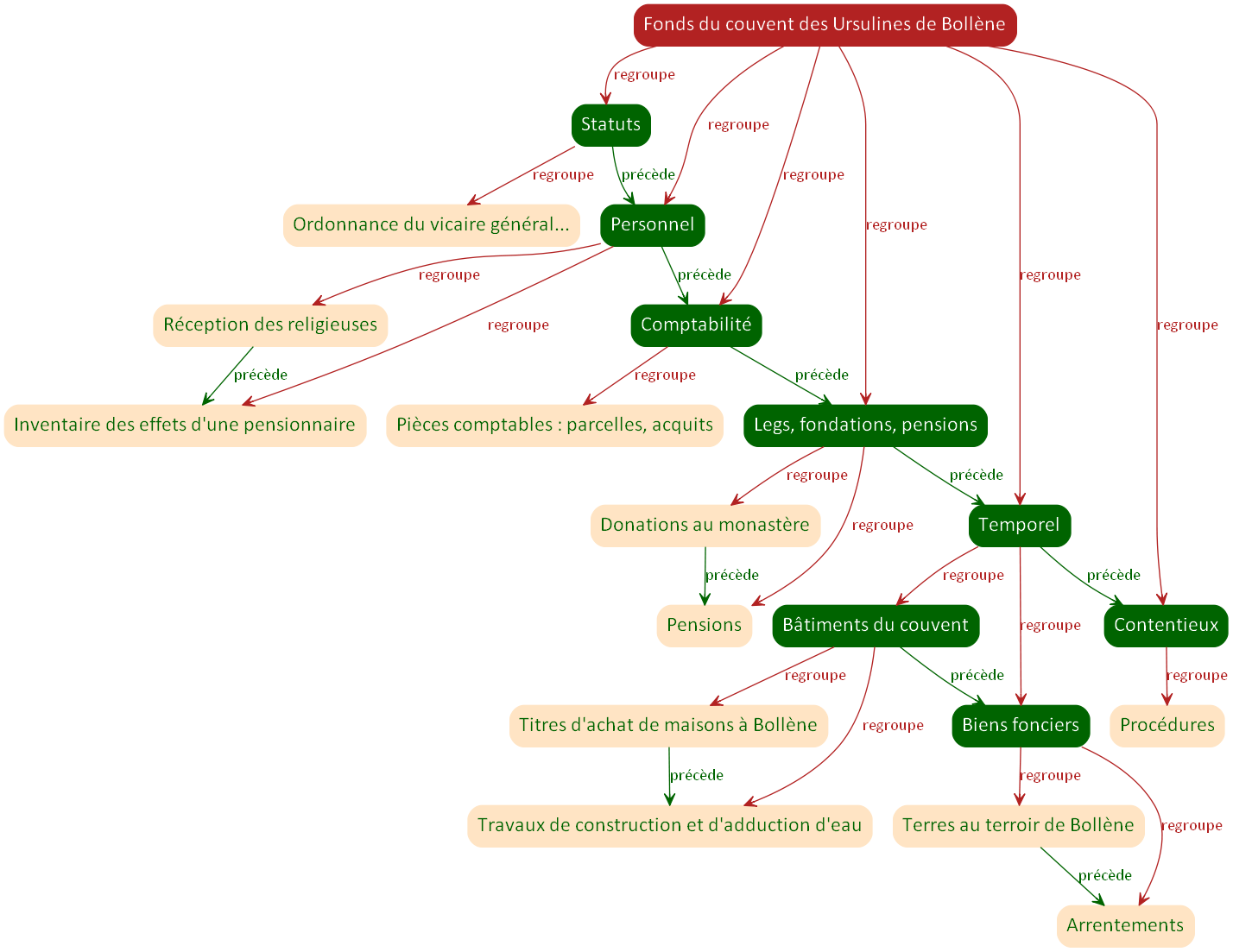
On a nommé ici deux types de propriétés. Ces noms de propriété n’ont rien d’officiel, ils ne sont là que pour expliciter aussi clairement que possible la nature de ces propriétés.
- Un composant parent regroupe (normalement) plus d’un composant enfant (dans la pratique, on rencontre des cas où un composant parent n’a qu’un composant enfant : cela peut correspondre à un défaut de structuration).
- Les composants d’un même niveau ont été ordonnés par l’archiviste suivant un critère qui peut être chronologique, alphabétique ou de toute autre nature. On dit ici qu’un composant précède un autre.
Cette représentation est toujours hiérarchique : on a une racine correspondant au fonds du convent des Ursulines de Bollène, avec des sous-parties, des sous-sous-parties.
Dans les représentations suivantes, nous prenons progressivement en compte des relations supplémentaires qui sont bien présentes dans l’instrument de recherche, parfois sous forme plus ou moins structurée, souvent sous forme littérale.
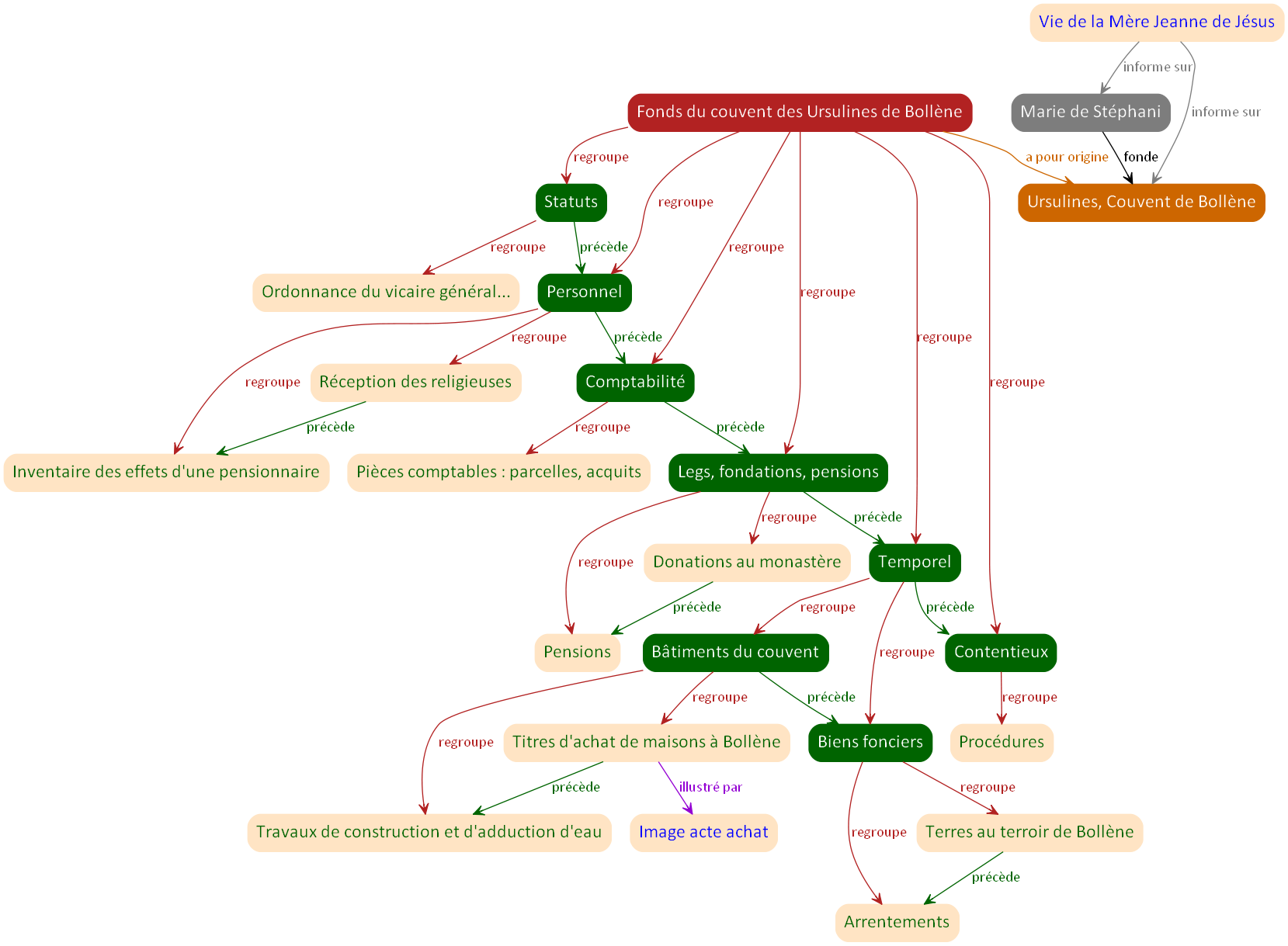
D’où proviennent les documents ?
Un archiviste, on s’en souvient, doit indiquer l’origine du fonds qu’il décrit. Dans l’instrument de recherche des archives de Vaucluse, il est clairement indiqué, dans l’indexation du producteur, qu’il existe une personne morale « Ursulines, Couvent de Bollène » qui est à l’origine du fonds.
Il est également intéressant de noter, dans la présentation du fonds, à la partie « Éléments historiques » : « L’an 1609, une communauté d’ursulines […] est installée à Bollène par Marie de Stéphanie, fondatrice de celle de Valréas six ans plus tôt. ».
Ainsi, nous avons tout naturellement un producteur, mais une mention supplémentaire d’une personne qui semble avoir fondé la communauté de Bollène, et qui, précision intéressante, avait également fondé précédemment celle de Valréas (nous pourrons revenir sur ce point par la suite).
La représentation ci-dessous prend en compte ces nouveaux éléments d’origine du fonds.
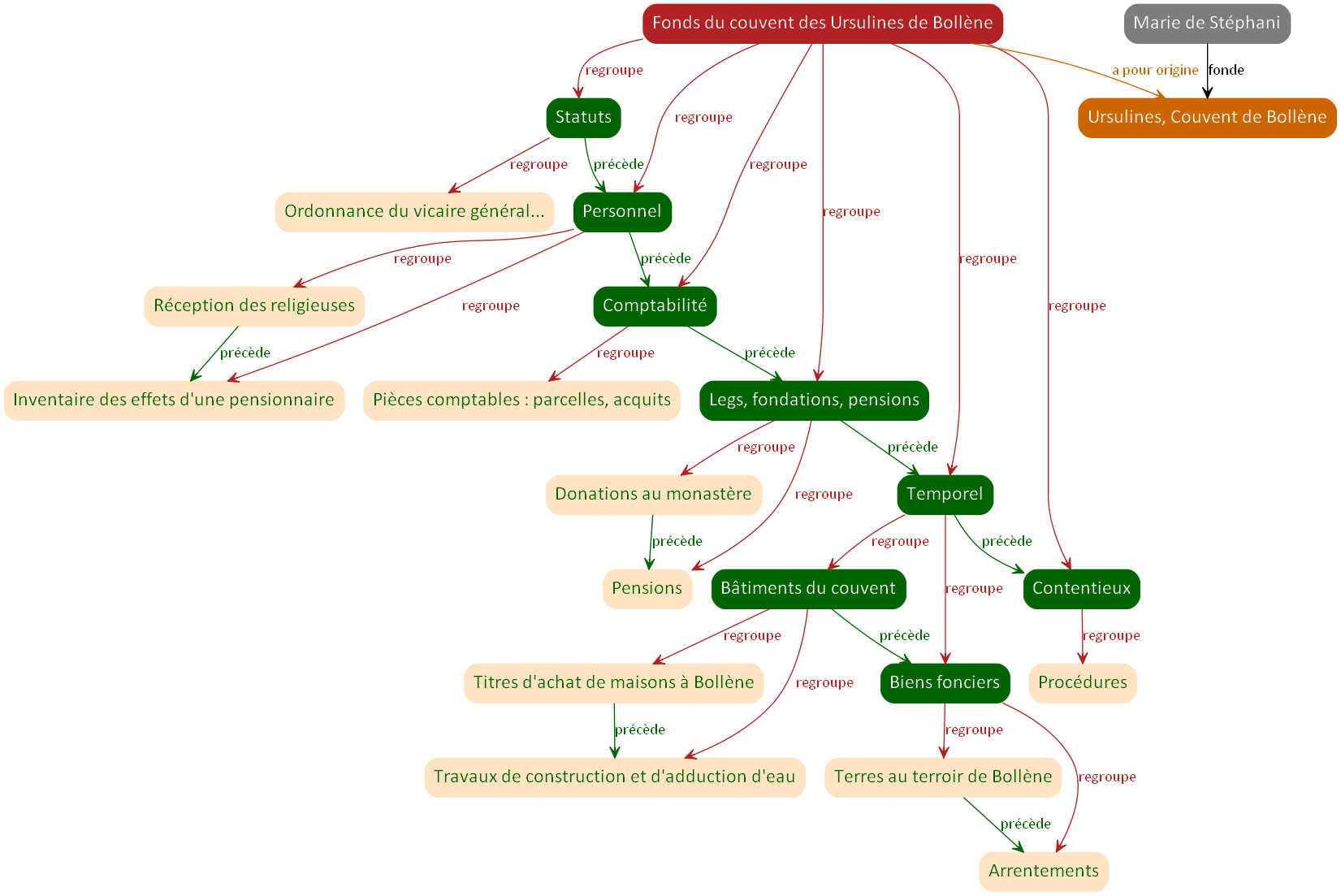
On peut noter dès à présent que cette représentation, dans son ensemble, ne répond plus au modèle arbre : on n’a plus une racine unique. La partie concernant le fonds lui-même est toujours en mode arbre, mais nous avons désormais ajouté de nouvelles relations qui sont à l’extérieur de cet arbre.
Sources externes et autres liens
Un ouvrage intéressant notre sujet, « Vie de la Mère Jeanne de Jésus, religieuse Ursuline, fondatrice des monastères de Ste Ursule, de l'ordre réformé de St Augustin, dans les villes d'Arles, d'Avignon, de Tarascon, de Valréas, de Bollène et de St Remy », est accessible en ligne. Cette référence peut parfaitement s’intégrer dans notre représentation au titre de source complémentaire, précisément de référence bibliographique.
Le fonds du couvent des Ursulines de Bollène n’est pas numérisé. Les archivistes de Vaucluse ont pris comme principe d’illustrer leurs instruments de recherche par quelques images d’une partie des documents. Ici, un document légendé « Achat de maison à Martin Bonjean, 1620 (97 H 7) » illustre l’article « Titres d'achat de maisons à Bollène ». Notons bien qu’il s’agit ici d’une illustration et non d’une reproduction systématique des documents décrits.
La représentation suivante prend en compte ces deux nouveaux éléments.
Mais, au fait, que décrivons-nous ?
La question que nous devons peut-être nous poser maintenant est : mais, au fait, que représente notre graphe ?
- Le fonds ? Pas seulement depuis que nous avons enrichi notre représentation avec des éléments liés à son origine, à des sources complémentaires…
- L’instrument de recherche décrivant le fonds ? Surtout pas. C’est là une confusion qu’il faut à tout prix éviter. Il est important de bien distinguer différentes notions.
Nous présentons une dernière représentation avec les principales entités en relation avec le fonds en question.
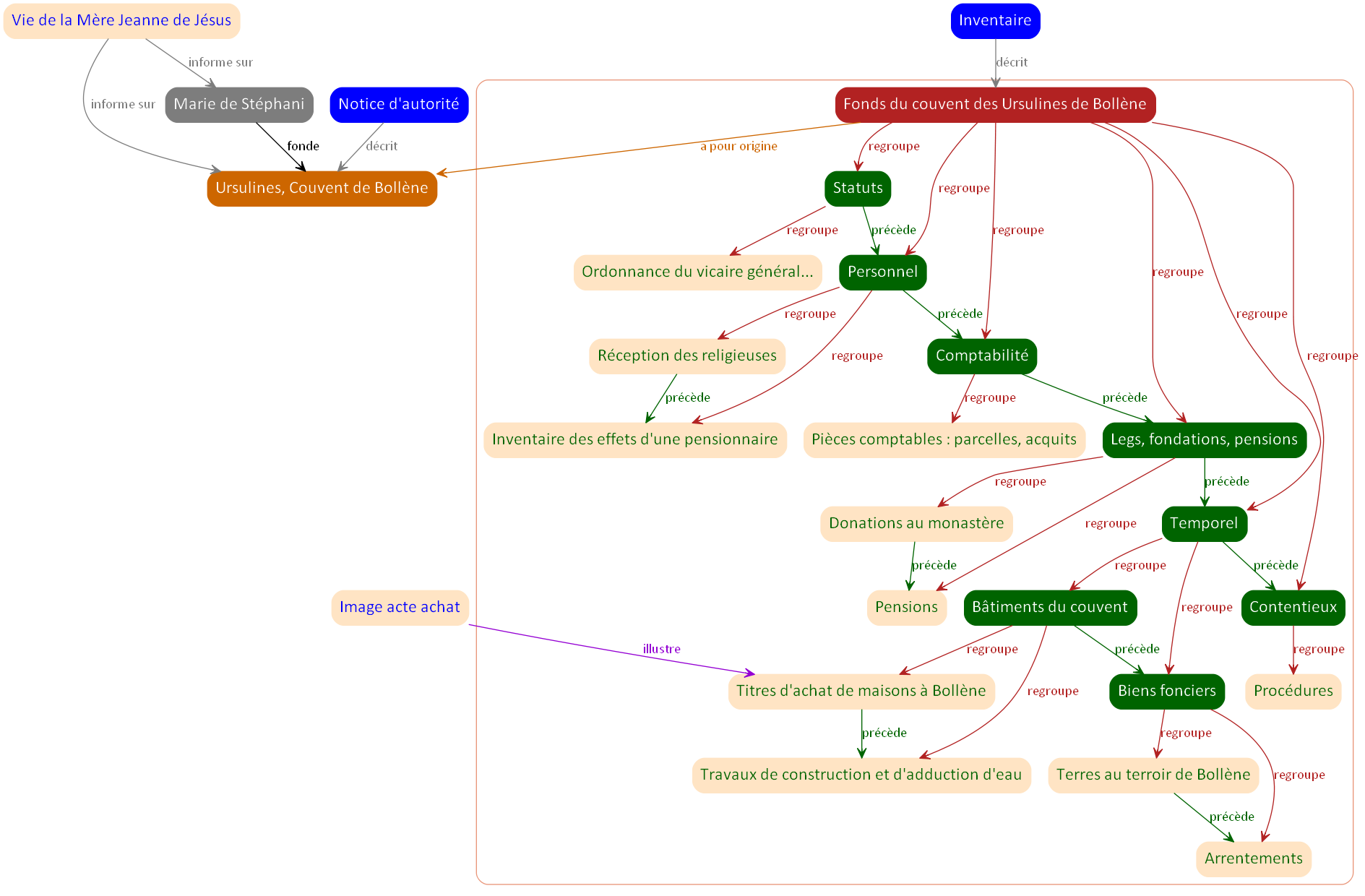
Dans ce dernier schéma, nous avons entouré d’un filet de couleur saumon, les éléments qui représentent le fonds et ses différents constituants. On y retrouve exactement notre première représentation en graphe.
Faisons maintenant intervenir l’archiviste. Celui-ci décrit chaque élément constitutif du fonds : le fonds lui-même et ses différents composants, ceci à plusieurs niveaux.
En réalité, ce que représente la partie encadrée de notre schéma, ce sont les composants du fonds et l’organisation de ces composants, mais tels que les archivistes qui ont travaillé sur le fonds les ont perçus et décrits. Pour chaque composant, les archivistes ont rédigé une notice descriptive et ce sont seulement ces notices descriptives qui sont accessibles, au moins dans un premier temps, aux publics. Ces notices se réfèrent aux documents eux-mêmes, identifiés par leur cote s’il s’agit de document matériels. Dans le cas de documents numérisés ou nativement numériques, les notices descriptives peuvent y donner directement accès.
Ici encore, la distinction entre les entités que l’on décrit et les descriptions que l’on produit n’est pas toujours aisée à faire. Il faut bien en être conscient.
Dans notre représentation, les notices descriptives des composants du fonds ont une existence par elles-mêmes. C’est-à-dire qu’elles ne sont pas seulement des éléments non isolables d’un document – un instrument de recherche ou inventaire – mais des métadonnées descriptives autonomes. C’est grâce à ça qu’elles peuvent être assemblées de différentes manières, destinées à différents supports, suivant différents formats, pour différents usages.
Dans notre schéma, nous avons fait figurer un inventaire, qui existe bien, qui a une identité propre et qui est actuellement en ligne à l’adresse déjà mentionnée. Cet instrument de recherche est un document à part entière, qui a son existence propre, indépendante de la représentation du fonds que nous faisons ici.
On notera que l’image qui illustre un composant précis du fonds est également représentée à l’extérieur de la représentation du fonds lui-même. En effet, il s’agit d’une copie numérique d’un document particulier, et cette copie numérique ne fait pas elle-même partie du fonds. Elle est un autre document.
Là encore, la distinction est importante car il nous est déjà arrivé, au cours de formations, de rencontrer des situations où des documents avaient été numérisés et où les archivistes, même formés et compétents, décrivaient, dans un même instrument de recherche, tantôt les documents eux-mêmes, tantôt leur copie numérique, dans la plus grande confusion.
L’archiviste qui décrit le fonds peut également être conduit à décrire le producteur dans une notice d’autorité que nous avons également figurée dans le schéma.
Les différents éléments présents ou seulement évoqués dans notre schéma
Nous allons récapituler les différents éléments présents ou seulement évoqués dans notre schéma pour bien différentier les entités qui composent ou sont en relation avec un fonds (et ici, un tout petit fonds de seulement 20 centimètres linéaires !).
- Les documents eux-mêmes, les archives, on dit aussi, dans le vocabulaire du web sémantique, les ressources archivistiques. Nous faisons seulement référence à ces documents, qui existent bien et sont conservés aux archives départementales de Vaucluse mais ne sont pas présents dans notre représentation.
- Des notices descriptives de ces ressources archivistiques. Dans notre schéma, ces notices ne sont pas reproduites in extenso, mais on lit seulement les intitulés que les archivistes ont utilisés pour identifier les documents correspondants. À titre d’exemple, une notice descriptive telle que dans l’instrument de recherche actuel est reproduite ci-dessous.
- La reproduction numérique d’un des documents du fonds est citée et le lien qui permet de l’atteindre est donné.
- L’instrument de recherche relatif à ce fonds et qui est mis en ligne sur le site des archives de Vaucluse est cité. Il s’agit d’un instrument de recherche électronique, d’un document à part entière produit par les archivistes.
- Notre schéma cite la personne morale qui est à l’origine du fonds : son producteur, le couvent des Ursulines de Bollène.
- Une notice d’autorité est supposée décrire le producteur. Elle est ici simplement citée, on donnerait la référence de cette notice et, si elle est accessible en ligne, le lien qui permet de l’atteindre.
- Il cite également la personne physique qui a fondé l’institution productrice du fonds. Nous n’avons, a priori, pas de notice décrivant cette personne.
- Mais, un ouvrage accessible en ligne nous donne des informations à la fois sur le couvent des Ursulines de Bollène et sa fondatrice, Marie de Stéphanie.
D’autres fonds en relation
Si l’on regarde avec un peu d’attention les descriptions des fonds des différents couvents des Ursulines en Vaucluse, on note – et cela n’a rien d’étonnant – qu’il existe des relations entre ces différentes institutions, en particulier des relations d’origine.
Dans les « éléments historiques » de la présentation des différents fonds, on trouve, sous forme littérale, des informations qui nous permettent de faire des liens entre les différents fonds :
- Concernant le fonds du couvent des Ursulines de Bollène : « L'an 1609, une communauté d'ursulines congrégées […] est installée à Bollène par Marie de Stéphani, fondatrice de celle de Valréas six ans plus tôt. ». Cette information est d’autant plus intéressante que, pour le couvent de Valréas, aucune mention de la date de fondation n’est donnée. On peut déduire que ce couvent a donc été fondé en 1603 environ. Ce fonds, de très petite taille (1 cm), n’a pas donné lieu à un instrument de recherche, mais seulement à une notice descriptive.
- Dans le fonds du couvent des Ursulines de Malaucène : « À la demande de l'évêque de Vaison, Joseph-Marie de Suarès, le monastère des Ursulines de Valréas envoie six religieuses à Malaucène, en 1639, pour y fonder une communauté… ».
Sur le site des archives de Vaucluse, on trouve :
- Pour les Ursulines de Malaucène, un instrument de recherche
- Pour les Ursulines de Valréas, nous ne disposons que d’une notice descriptive très sommaire.
Ci-dessous le dernier schéma.
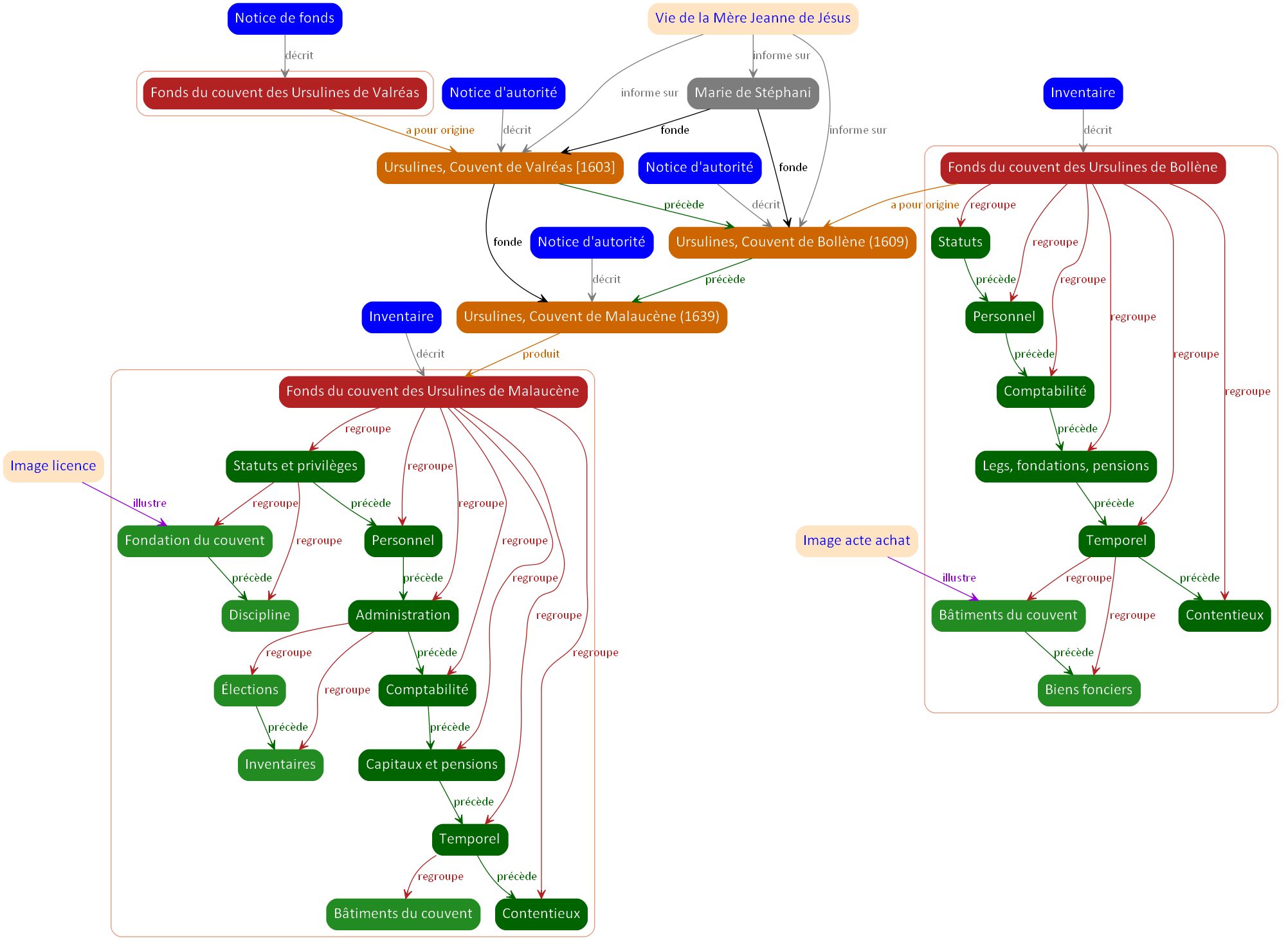
Nos schémas sont loin de restituer l’ensemble des relations qui peuvent exister entre les différentes entités en lien avec les ressources archivistiques. Par exemple, nous n’avons jamais représenté les sujets des documents et les relations qui peuvent exister entre ces sujets.
Notre ambition était seulement de donner, à partir d’un cas simple, une idée des possibilités offertes par le modèle graphe. Ceci d’autant que les liens pourront se faire en partie manuellement, mais aussi en partie automatiquement.
Pensez-vous qu'il s'agit d'une remise en cause ou, au contraire, d'un prolongement de la pratique archivistique ?
D'un nouveau gadget ou d'un réel enrichissement de nos usages ?
Les internautes pourront-ils y trouver une valeur ajoutée ?
Je ne peux que souscrire à l’idée que vous présentez ici, je l’avais d’ailleurs exploré dès 2009 dans deux billets http://www.lespetitescases.net/carcans-de-la-pensee-hierarchique-et-documentaire-1 et http://www.lespetitescases.net/carcans-de-la-pensee-hierarchique-et-documentaire-2 .
Avec le recul, si le modèle de graphe reste une solution très intéressante (si ce n’est le plus intéressant jusqu’à présent) pour représenter les données archivistiques et plus généralement patrimoniales, je n’ai à ce jour jamais vu d’interfaces graphiques qui en exploitent le potentiel et en restituent la complexité. De même, il pose aussi de nombreuses questions quant à son édition et sa maintenance.
Enfin, trois aspects plus techniques doivent être pris en compte : les technologies de graphe peuvent poser des problèmes de montée en charge qui ne sont pas encore complètement résolus (même si des progrès ont été faits), pour des raisons de contextualisation de certaines assertions (cf. http://www.lespetitescases.net/quel-evenement-ou-comment-contextualiser-le-triplet ), j’avoue regarder avec attention du côté des « property graph » au coeur de technologie comme Neo4j ou Apache Titan, ces technologies ne sont malheureusement pas la tasse de thé de la plupart des développeurs ce qui en limite l’adoption.
Un grand merci, Gautier, pour ce commentaire, et à plusieurs titres.
Tout d’abord, nous n’oublions pas, chez Anaphore, que vous faites partie de ceux qui nous ont sensibilisés aux données liées, à Carnac, lors de ce passionnant séminaire INRIA IST 2012 « Le document numérique à l’heure du web des données ».
C’est une très bonne idée de redonner les liens sur votre blog. Il y a matière à réflexion, pour les archivistes, dans ce que vous écriviez, déjà en 2009 et même avant, et dans les échanges qui s’en sont suivi, de même qu’à travers les liens que vous et vos commentateurs donnez. Dans le second lien, en particulier, les présentations synthétiques que vous faites du protocole OAI-PMH, de la DTD EAD et du web des données constituent un excellent point de départ pour une réflexion indispensable.
Enfin, les pistes techniques que vous évoquez avec les « property graph » et Neo4J en particulier sont précieuses.
Notre objectif, chez Anaphore, est de tenter de mettre à la disposition des archivistes des outils pratiques leur permettant de bénéficier, en douceur, des nouvelles possibilités que vous évoquez. D’où notre travail, avec Thomas Francart, sur une ontologie pour la description archivistique. D’où nos travaux sur la « diffusion multidirectionnelle de métadonnées descriptives de ressources archivistiques » encouragés par le ministère de la Culture et de la Communication et le SIAF.
Le texte présent n’avait d’autre ambition que d’illustrer, à partir d’un exemple simple, l’intérêt d’aller au-delà du modèle hiérarchique.
Concernant votre invitation à dépasser le modèle hiérarchique, elle reste complètement fondée. Si la notion de respect des fonds est, bien sûr, fondamentale, le risque est de considérer le fonds comme une île. Un archiviste me faisait remarquer que, dans les archives publiques, seul le point de vue de l’administration est présent, jamais celui de l’administré. De même, si l’on prend l’exemple d’un fonds d’entreprise privée, la vie de cette société ne peut être comprise en dehors de ses clients qui la font vivre, de ses fournisseurs sans lesquels elle ne pourrait rien produire, sans des références à un contexte économique, à des évolutions techniques… qui expliquent ses périodes de prospérité, son déclin éventuel… Le rôle de l’archiviste n’est certes pas de faire l’histoire complète de ses producteurs, mais il est nécessaire que son travail, les techniques et les formats qu’il utilise permettent de franchir les barrières métier, de lier ses métadonnées descriptives à d’autres. Cela se fait, d’ailleurs déjà, avec les généalogistes, même si les solutions actuelles « d’indexation collaborative » ne constituent pas la meilleure approche possible de la question. (Notons que, pour les données nominatives, le ministère de la Culture a dû produire un format spécifique Nomina). D’où les problèmes que posent aujourd’hui les formats métier. Je n’ai pas oublié, à ce propos, la réponse que vous m’aviez faite, à Carnac, sur l’opportunité d’un format spécifique aux archives pour les notices d’autorité : « une hérésie ».
En plus des questions de fond que vous posez, le problème, avec un format métier comme EAD, c’est qu’il est souvent mal utilisé. On arrive fréquemment à une application un peu aveugle et quasi-dévote d’une syntaxe au détriment des questions de contenus. Quand vous écrivez que la « DTD EAD est l’archétype même du schéma d’encodage XML conçu comme une transposition des habitudes issues du papier et des conditions de travail dans un monde non numérique », c’est d’autant plus vrai que, dans la pratique, des services ont fait encoder – c’est-à-dire simplement poser des balises XML-EAD – sur d’anciens instruments de recherche. Tout ça est, aujourd’hui (peut-être seulement demain), bon pour la poubelle.
Les réserves que vous exprimez sur les interfaces graphiques sont tout-à-fait justifiées. En ce qui nous concerne, nous avons fait un premier travail, mais des plus simples, qui consiste à générer automatiquement, avec notre outil de description archivistique, un fichier au format DOT représentant l’organisation des descriptions. GVEdit/Graphaviz permet alors de visualiser très simplement le résultat. Nous présenterons ce mode de restitution très prochainement, mais il s’agit plus d’un exercice que d’une filière exploitable.
D’ailleurs, nous restons là dans un modèle essentiellement hiérarchique, même avec une restitution graphique. Ne faudrait-il pas, mieux que nous l’avons fait dans ce qui précède, distinguer le modèle, qui permet aux machines de parcourir des graphes qui ne sont pas visibles par l’humain, des représentations graphiques dont nous parlons ici ? Les réserves que vous exprimez concernant, si je comprends bien, uniquement les secondes.