
Dans un billet précédent, nous avions présenté les travaux de bibliothécaires et chercheurs qui ont abouti à une nouvelle génération de moteurs de recherche.
Il était, bien entendu, tentant de s’inspirer de ces travaux et d’utiliser les outils disponibles pour élaborer un moteur de type nouveau pour les archives.
Un certain nombre de questions se posait, compte tenu des spécificités de la description archivistique – description à plusieurs niveaux principalement – et des options étaient à prendre pour obtenir, dans un contexte plus complexe que celui des bibliothèques, des résultats satisfaisants et nettement plus pertinents que ceux des différents moteurs existants.
Après plus de deux années de définition du projet, de développements, de tests et d’ajustements, il est temps de présenter Bach, moteur de recherche de nouvelle génération développé au sein de la société Anaphore.
Rappel sur les principales caractéristiques des moteurs de recherche de troisième génération
On se rapportera, bien entendu, au post déjà cité et, mieux encore, à l’ouvrageCatalogue 2.0 : The future of the library catalogue. Edited by Sally Chambers. Facet Publishing, 2013. ISBN 978-1-85604-716-6 qu’il s’est contenté de résumer très partiellement.
Nous rappelons rapidement les principales caractéristiques de ces moteurs.
A. Un principe de base
Le modèle booléen – qui a été utilisé jusqu’à présent, et est encore utilisé – présente un certain nombre de limites en recherchant une correspondance exacte entre les termes d’une requête et les termes présents dans les descriptions disponibles.
Un nouveau modèle, dit vectoriel, utilise un mécanisme de recherche de correspondance optimale (et non pas exacte) entre ces deux catégories de termes.
De plus, des algorithmes élaborés de calcul de pertinence permettent de classer les réponses.
Grâce à ces deux mécanismes, ces moteurs permettent d’avoir des réponses – pertinentes – qu’un moteur de précédente génération n’aurait pas retournées. Et les réponses les plus intéressantes sont présentées en tête de liste.
La requête commence donc généralement par la saisie d’un ou plusieurs termes. Ce mode de recherche correspond aux habitudes prises par les internautes avec les moteurs grand public. Et il n’est plus nécessaire de maîtriser un langage de requête ni l’utilisation des opérateurs booléens.
B. Des suggestions de termes
En cours de saisie des termes d’interrogation et après validation de la recherche, le moteur suggère des termes possibles pour la requête.
C. Des outils linguistiques
Ces moteurs intègrent généralement des outils qui permettent de remédier aux fautes de saisie (tolérance orthographique), de prendre en compte les différentes flexions d’un mot (masculin-féminin, singulier-pluriel, conjugaison des verbes), les dérivés (noms-adjectifs), de gérer la synonymie…
D. Un affinage des réponses intuitif et par étapes
Dans le cas où les réponses retournées par la requête initiale sont nombreuses, il est possible de les affiner progressivement et intuitivement, grâce à des « facettes » (ou filtres). Celles-ci peuvent être textuelles ou graphiques.
Les spécificités archivistiques
Elles sont de plusieurs ordres et complexifient notre problématique.
A. La description à plusieurs niveaux
Le principe de description à plusieurs niveaux, qui aboutit à la production d’instruments de recherche hiérarchisés, a plusieurs conséquences, principalement sur la recherche par le moteur et sur la façon de restituer les résultats.
1. Sur le fonctionnement du moteur
Les bibliothécaires mettent principalement à disposition de leurs publics des notices catalographiques. Certes, ils peuvent également produire, par exemple, des catalogues thématiques regroupant de nombreuses notices organisées par rubriques. Mais, dans tous les cas, chaque notice contient l’ensemble des éléments nécessaires à la description d’un ouvrage ou de tout autre document.
Dans la pratique archivistique, la description à plusieurs niveaux est de nature différente : chaque niveau ne dit généralement pas tout de la ressource décrite. En effet, sauf au niveau de description le plus haut, une partie des informations descriptives qui permettent d’appréhender cette ressource est consignée dans une ou plus d’une ressource parente. Une description, au niveau le plus bas, peut, par exemple, se limiter à une année. Cela pose, on le comprend, un problème a priori pour la recherche. Pour que le moteur fonctionne, il va falloir gérer l’héritage des informations descriptives pertinentes d’un niveau parent à ses enfants. Mais, il faut que cet héritage soit géré le plus intelligemment possible. Sans héritage, on génère énormément de silence. Avec trop d’héritage on obtiendra beaucoup de bruit. Dans tous les cas, cet héritage ne pourra fonctionner correctement que si la conception, en amont, des instruments de recherche, a été faite de manière intelligente.
2. Sur la présentation des résultats
Les moteurs de recherche des bibliothèques présentent les résultats d’une requête sous forme de liste simple.
Faut-il faire de même pour les archives ou présenter les résultats dans leur contexte organique ? Question importante et la réponse que l’on pourrait donner dépend de qui la donne. On ne caricature pas trop si l’on dit que souvent l’archiviste souhaitera la réponse dans son contexteOn pourra revenir, à ce sujet, sur le billet La description archivistique à l’ère du numérique – Part 1 et au commentaire : « Il faut avoir fait l’école des Chartes pour utiliser ça ! » alors que le public en général, même averti, sera perdu si on ne lui présente pas une simple liste des documents qu’il attend .
Les éditeurs de moteurs pour les archives ont généralement privilégié la présentation des résultats dans le contexte. Nous avons pu constater, en interrogeant de nombreux utilisateursDans le même billet, nous avions aussi cité Eric Lease Morgan pour lequel l’instrument de recherche impose un point de vue propre à l’archiviste., que cette présentation est considérée comme hermétique.
Il faut revenir quelques instants sur la distinction que nous avions soulignée, dans un autre billet, entre données et document pour les descriptions archivistiques. Les moteurs de recherche fonctionnent en mode données et les instruments de recherche sont des documents et ne sont pas optimisés pour leur fonctionnement.
B. La diversité des ressources, de leur description, de leur indexation
Les moteurs pour les bibliothèques fournissent un accès à différents types de ressources : ouvrages, photographies, documents audiovisuels… Mais, ces différents documents sont décrits suivant des règles bien définies.
Pour les archives, les corpus – ensembles de ressources – comprennent les différents types de documents ci-dessus mais, potentiellement, pour toutes époques, toute origines (publiques, privées) concernant tous les domaines de l’activité humaine. Dans ce contexte, les règles de description des documents d’archives sont nettement moins formalisées que pour les bibliothèques, les modes d’indexation peuvent être adaptés aux différentes catégories de documents, tant pour leur forme que pour leur contenu.
Cette diversité des organisations des descriptions et des descripteurs qui servent de facettes complexifie la mise en œuvre des moteurs.
C. L’immensité de la tâche
Les services généralistes sont confrontés à des masses considérables de documents à traiter, avec des ressources humaines insuffisantes. Les descriptions ont été faites à des époques différentes, suivant des méthodes distinctes (la généralisation des normes de description ne date guère de plus d’une décennie), avec des outils souvent mal adaptés. Il s’ensuit une grande hétérogénéité des inventaires qui handicape leur mise en ligne.
Les choix effectués pour Bach
A. Les fonctions des moteurs de troisième génération
Malgré les difficultés prévisibles liées à la spécificité des descriptions d’archives, le pari d’Anaphore a été de mettre les caractéristiques des moteurs de troisième génération, rappelées ci-dessus, au service des descriptions d’archives.
Le moteur est d’abord à destination des publics, qui ont besoin de simplicité, d’intuitivité, d’outils graphiques et qui sont habitués aux moteurs de recherche grand public et commerciaux.
Pour autant, les spécialistes, en particulier les archivistes, ne devaient pas être oubliés et donc disposer de fonctions puissantes.
B. Recherche et navigation
Cette question est, on l’a vu, liée à la spécificité des descriptions d’archives.
Dans la pratique, on peut avoir besoin d’obtenir une réponse précise à une requête précise mais on peut également souhaiter partir à la découverte des ressources disponibles dans un fonds d’archives, voire un ensemble de fonds.
Bach veut offrir à la fois des possibilités de recherche simple et efficace qui conduisent à une liste de résultats et des possibilités de navigation grâce à une présentation structurée des instruments de recherche.
Si l’expérience passée nous a montré que vouloir imposer aux publics une fusion de la recherche et de la navigation aboutissait à des échecs, on doit pouvoir alterner et même associer simplement recherche et navigation.
Principales fonctions de Bach
A. La recherche
1. Une recherche textuelle intuitive et assistée
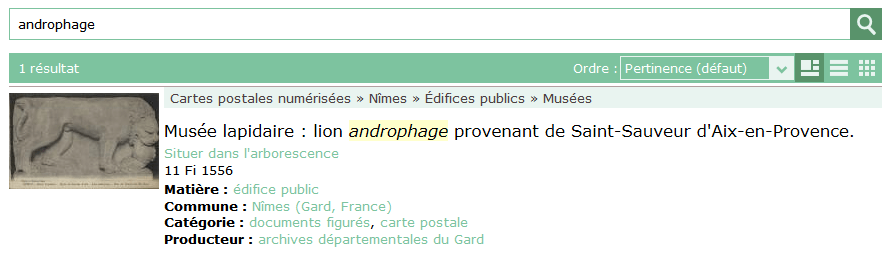
Ci-dessous quelques exemples de tolérance orthographique + flexions ou suggestions.
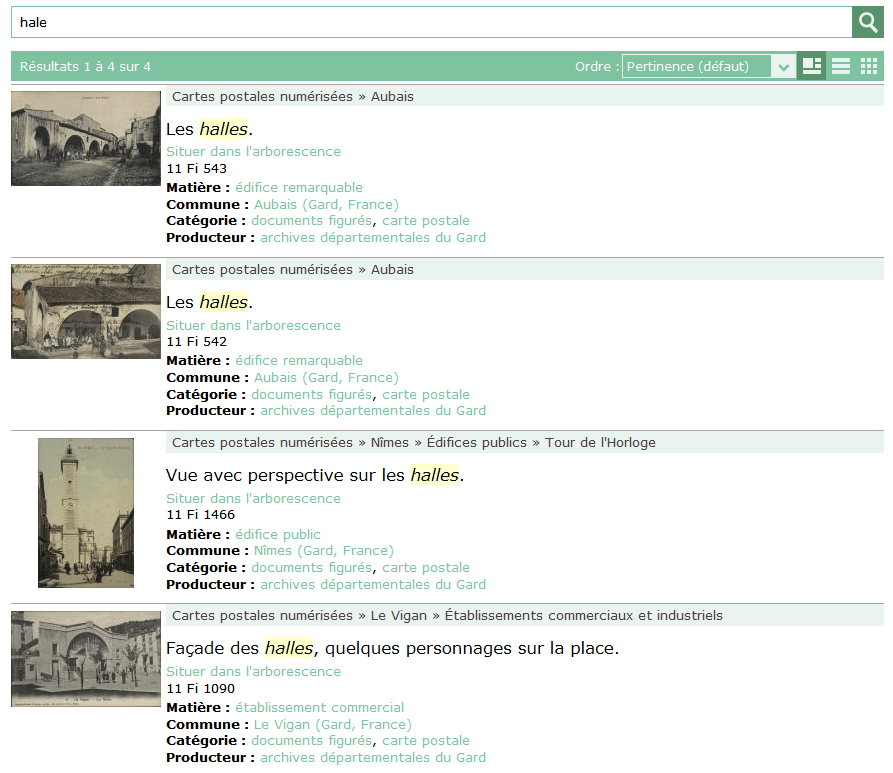

Un clic sur le terme suggéré relance la recherche.
2. Un affinement de la requête par les facettes
Une requête est lancée sur deux termes filature et soie.
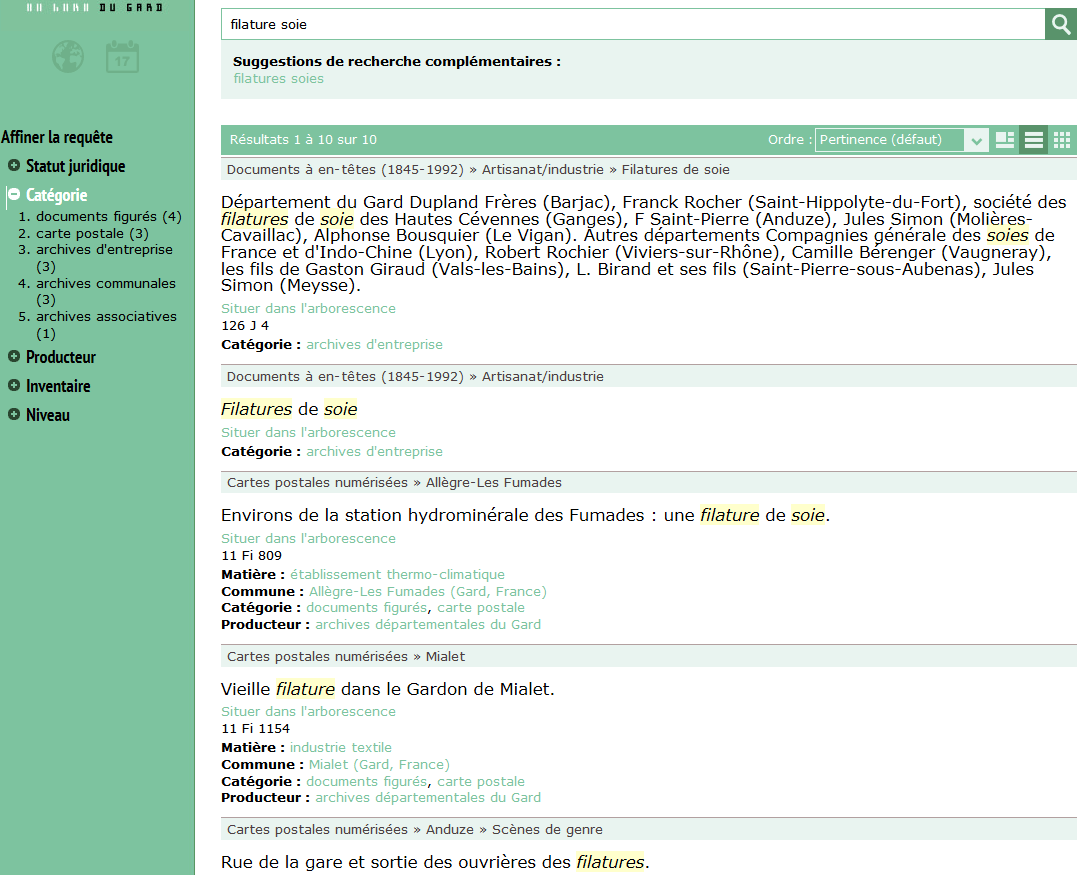
On peut, par exemple, filtrer sur la facette Catégorie avec archives d’entreprises.
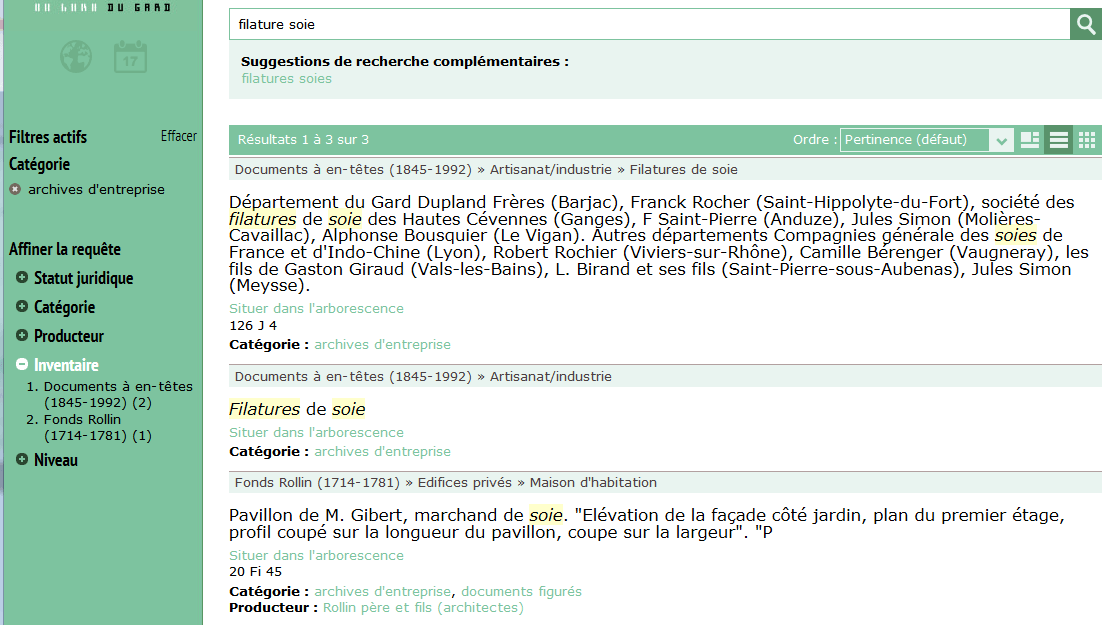
Le filtre sélectionné s’affiche comme filtre actif et il est possible de le désélectionner si les résultats ne nous conviennent pas.
3. Des facettes visuelles
En complément des facettes textuelles, on peut disposer de facettes graphiques : cartographiques et chronologiques.
Par exemple, une carte permet à la fois de localiser les réponses et de filtrer.
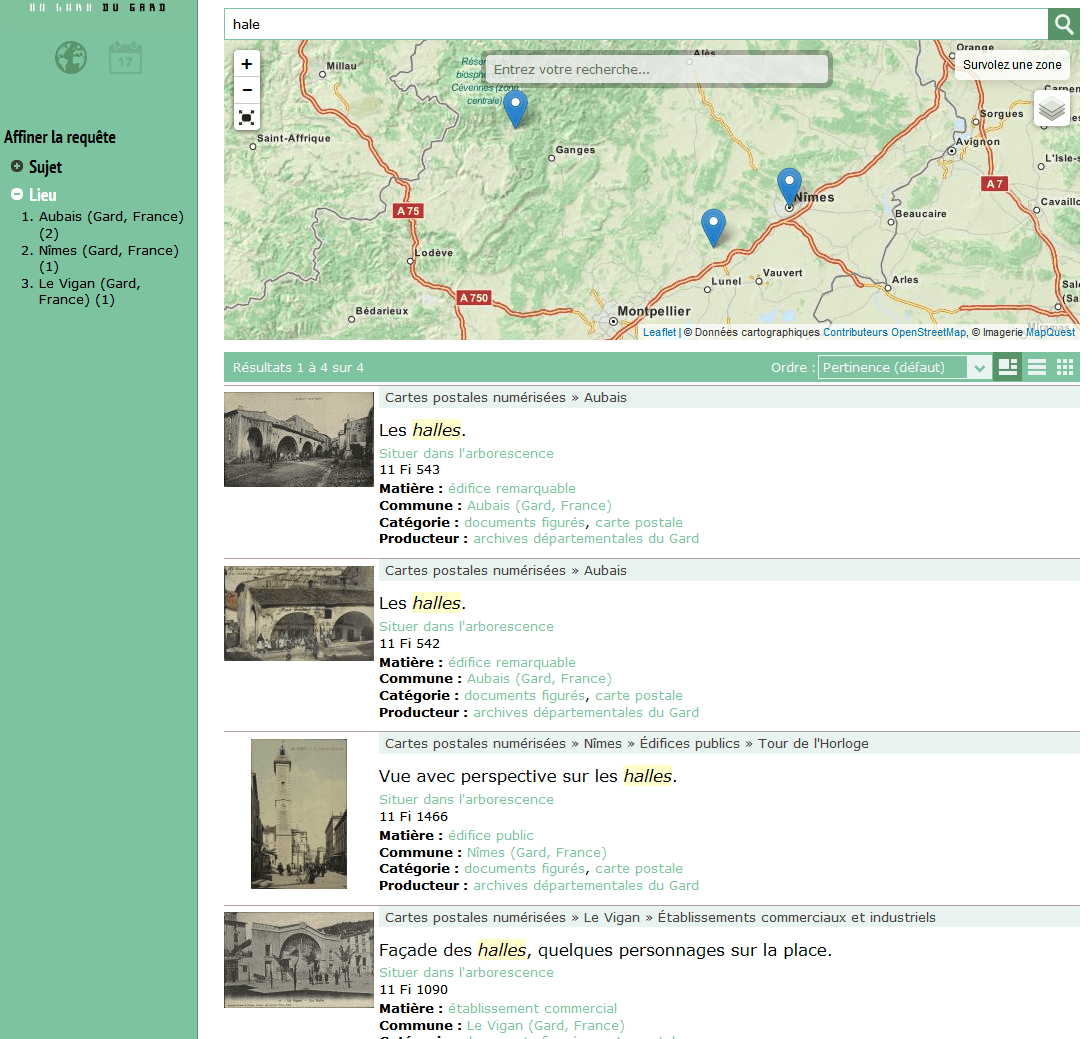
Une frise chronologique permet à la fois d’avoir une idée des périodes les mieux représentées et de filtrer sur une période choisie.
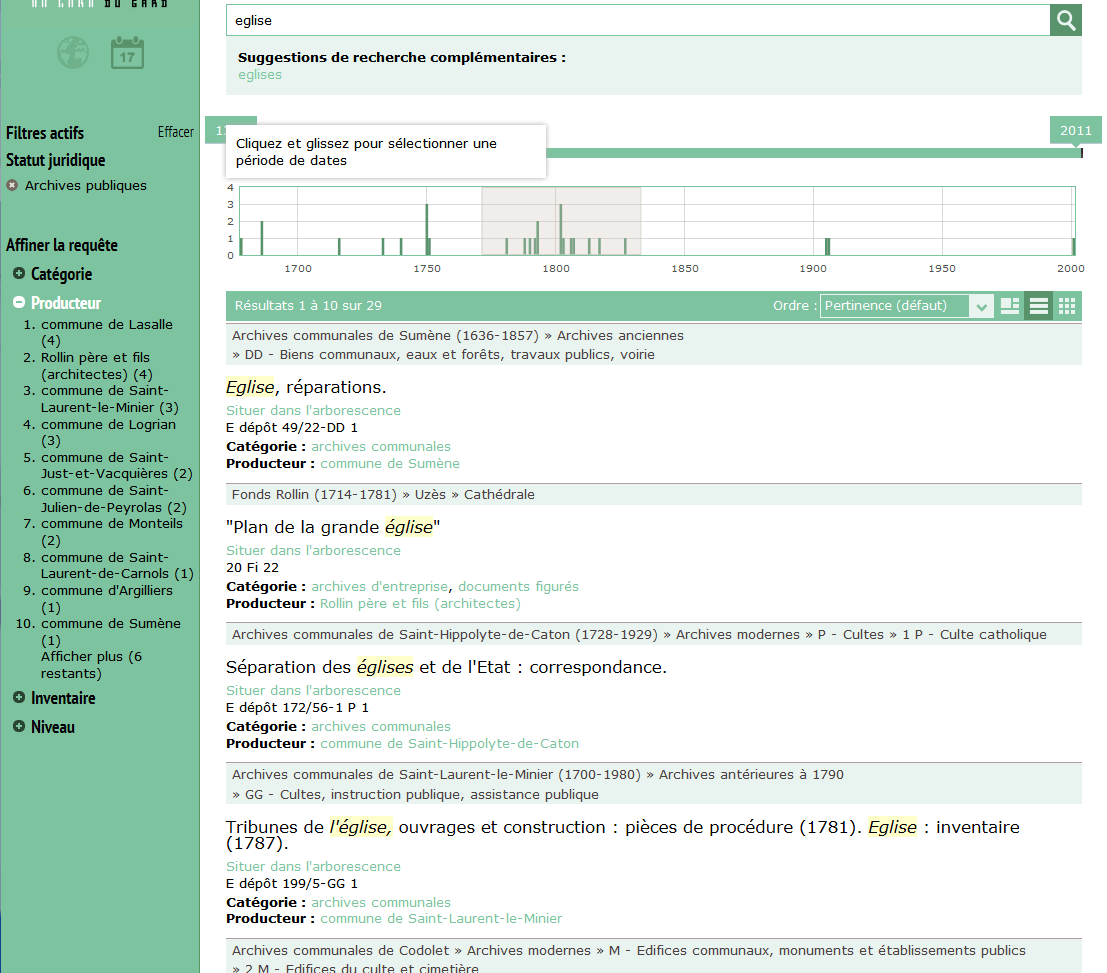
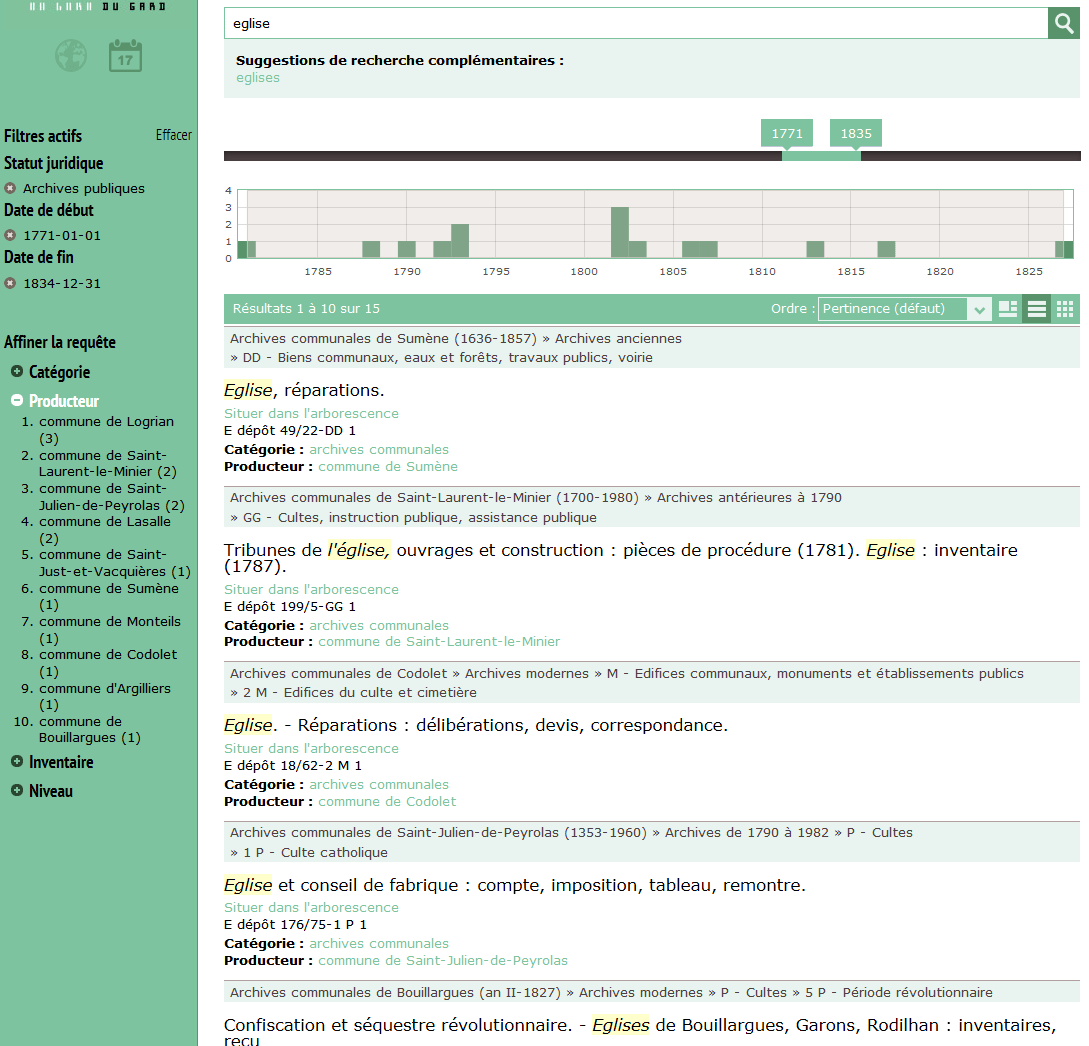
Le fait de draguer une zone sur l’histogramme chronologique a pour effet de préciser la requête. Le nombre de réponses passe de 29 à 15.
Il faut noter que les facettes s’ajustent automatiquement. On voit, par exemple, que la facette Producteur passe de 16 à 10 éléments (il n'y a plus "Afficher plus").
4. La présentation des résultats de recherche
Bach présente les résultats de la manière la plus simple possible, sous forme d'une liste.
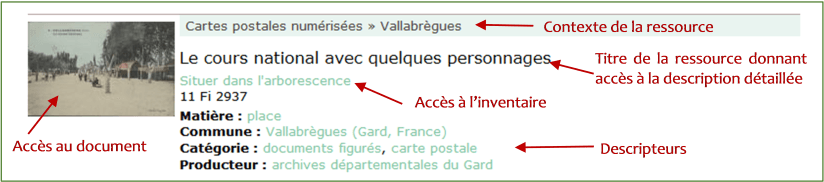
Plusieurs présentations sont possibles. Par défaut, il s’agit d’une liste comportant :
- Le contexte éventuel (niveaux parents) de la ressource. Ces différents niveaux sont cliquables.
- Les principaux éléments de description, en particulier l’intitulé ou titre de la ressource.
- Les descripteurs éventuels, cliquables.
- Un lien vers une fenêtre affichant le détail de la description (il suffit de cliquer sur le titre de la description).
- Un lien (Situer dans l’arborescence) donnant accès à l’instrument de recherche
- Un lien vers un ou plus d’un document numérique, s’il en existe.
Ce mode de présentation des résultats par liste permet d’avoir les informations essentielles de manière synthétique. Et, de plus, les détails, les documents numérisés, l’inventaire… tout est accessible par un seul clic.
D’autres modes de présentation des résultats sont possibles, comme les listes sans vignettes ou les mosaïques d’images.

5. Le tri des résultats
Par défaut, les réponses sont toujours triées par pertinence. Cette notion de pertinence correspond ici à une réalité, compte tenu du fonctionnement même du moteur. Par exemple, une interrogation halle aubais renverra toutes les descriptions comportant soit halle (ou halles) soit Aubais, soit les deux, mais les descriptions contenant les deux seront affichées en premier.
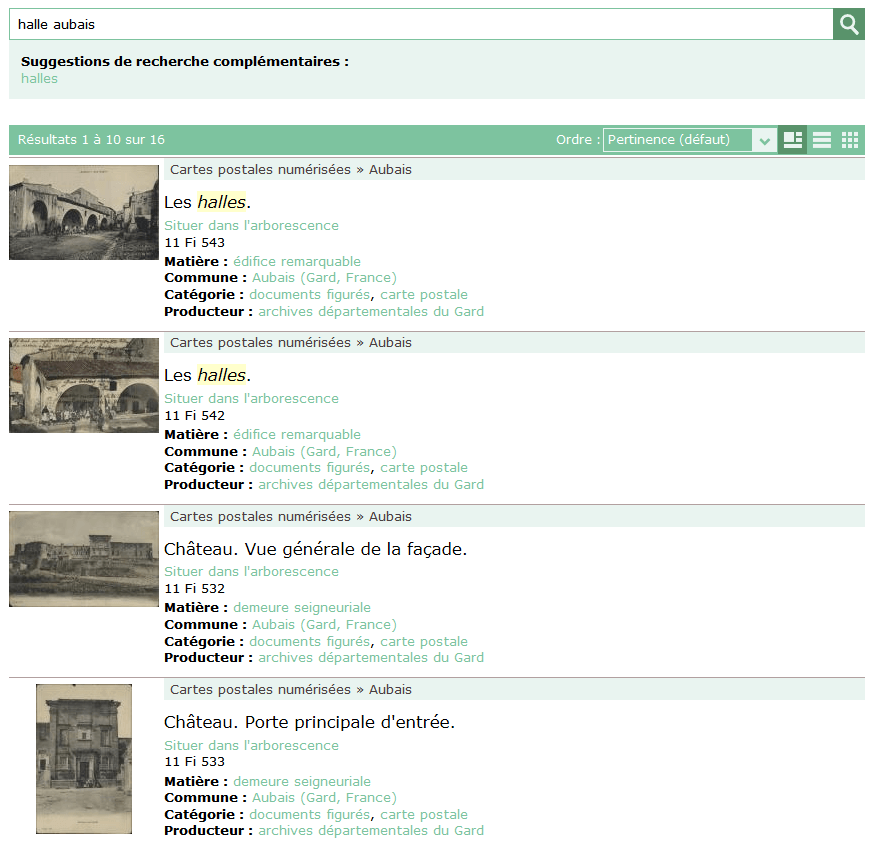
D’autres modes de tri sont proposés : alphabétique, chronologique et suivant la logique de l’inventaire (nous allons revenir sur ce dernier point).
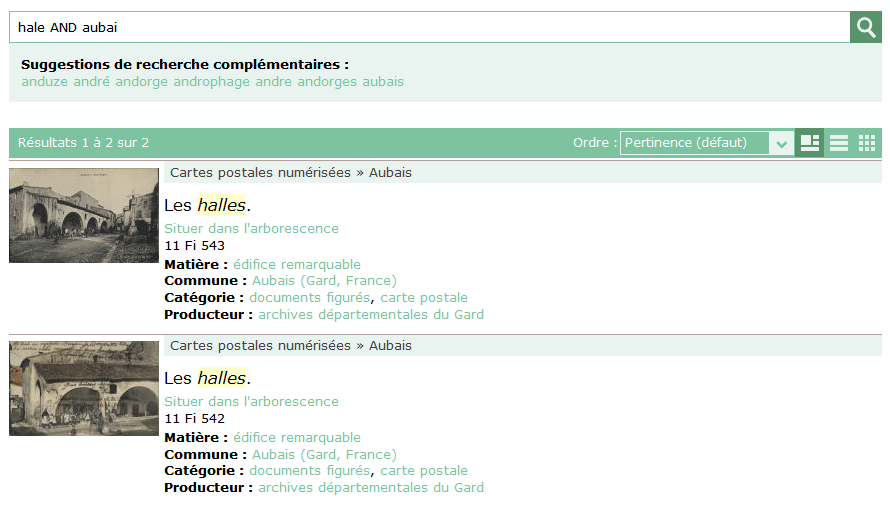
6. Le mode booléen n'est pas interdit
Notons, par parenthèses, que l’emploi des opérateurs booléens reste possible pour les habitués. Le modèle booléen reste donc accessible, tout en conservant l’avantage de la tolérance orthographique, comme le montre l’exemple suivant.
B. La navigation dans les inventaires
Bach offre un accès au cadre de classement, s’il existe, et aux instruments de recherche. Ces derniers sont accessibles par le cadre de classement et par les réponses (liste ou détail).
Il est ainsi possible de naviguer, à partir du cadre de classement ; de situer une réponse à une requête dans son contexte et de poursuivre, ainsi, une recherche par une navigation. Il est également possible, lorsque l’on est sur un inventaire, de lancer une requête. Celle-ci est alors lancée dans l’instrument de recherche correspondant. On revient alors sur la fenêtre de recherche et il est possible de lancer de nouvelles requêtes.
Ci-dessous un exemple de boucle de ce type.
On lance une requête précise, à l’aide d’une expression.
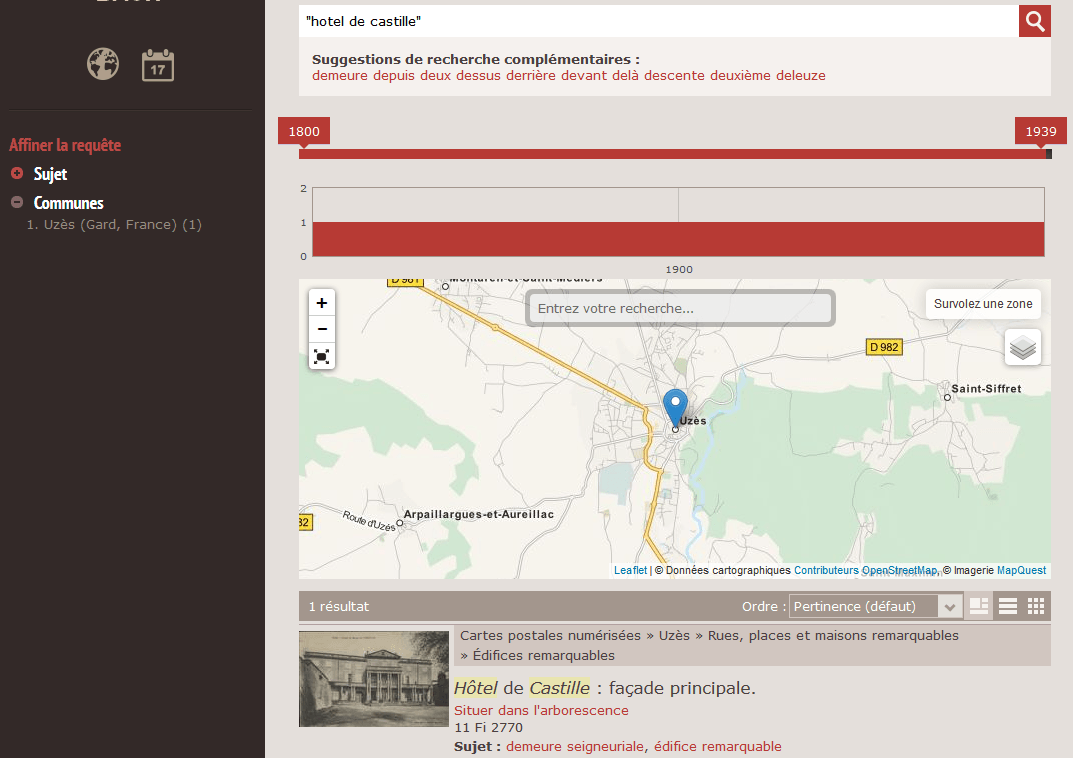
On obtient une réponse unique.
On clique sur "Situer dans l’arborescence". L’instrument de recherche hiérarchique s’ouvre ; la description correspondante se trouvant en haut de l’affichage et surlignée.
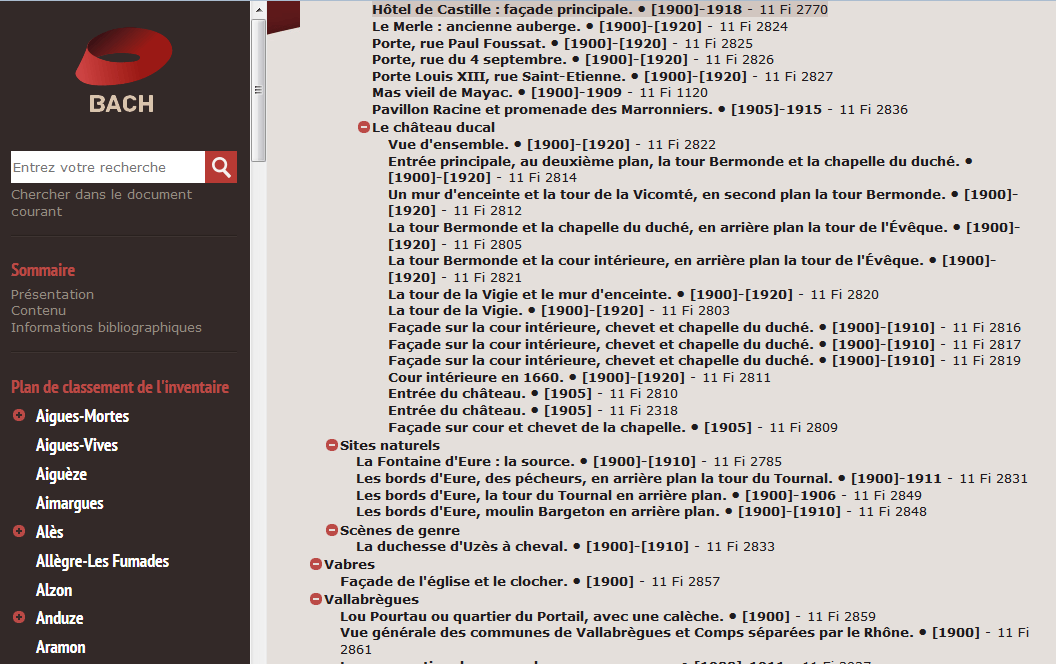
Un clic sur la ligne surlignée (ou sur toute autre) affiche le détail de la description.
Ce qui nous intéresse ici, c’est la zone de recherche.
Saisissons une requête.

En validant, nous nous retrouvons sur la fenêtre de recherche. Nous pouvons faire plusieurs remarques.
- Les réponses se situent toutes dans l’instrument de recherche d’origine, ce que confirme le filtre actif.
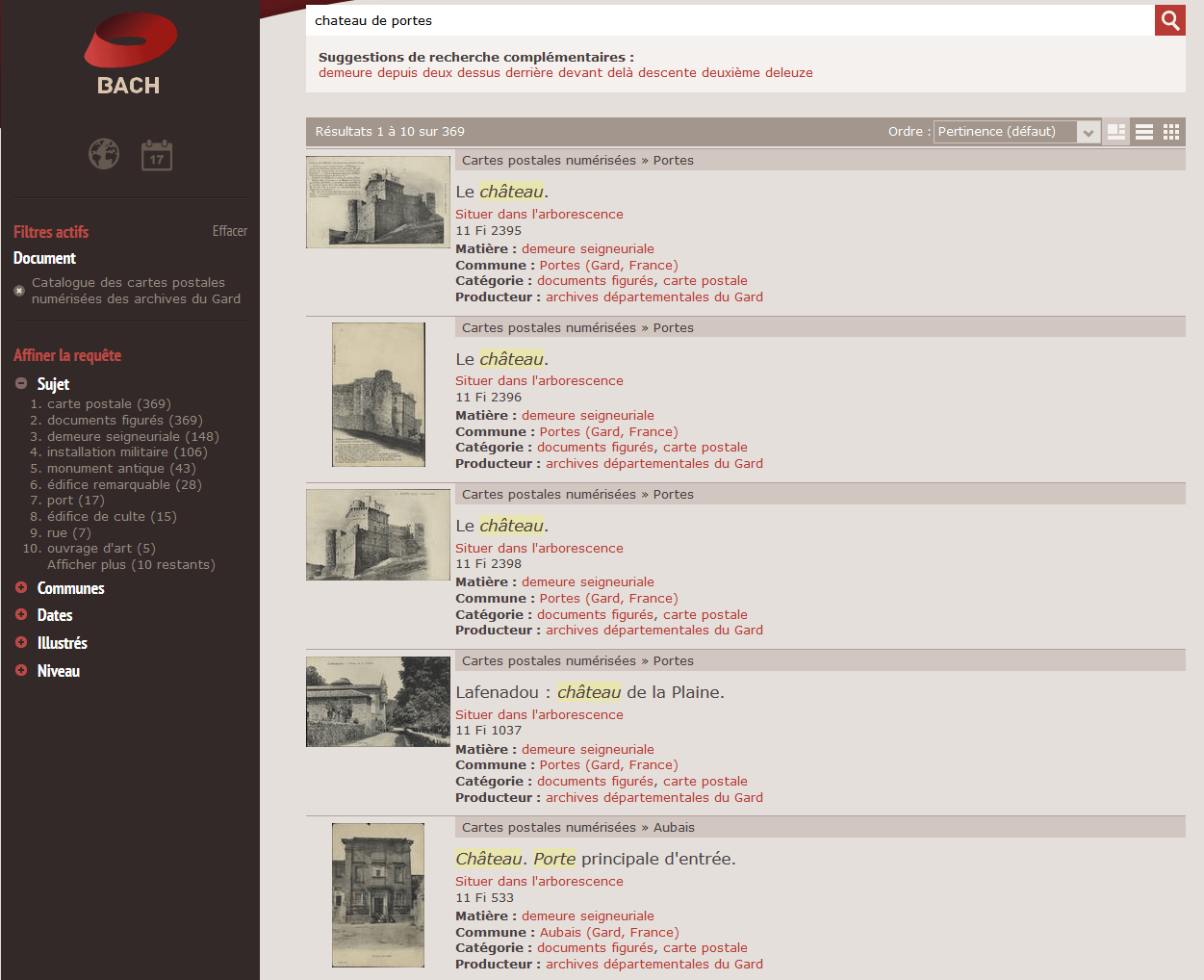
- Le nombre de réponses est important (369) puisque les descriptions contenant porte(s) ou château sont prises en compte.
- Les réponses contenant à la fois château et porte viennent en premier.
- Parmi celles-ci, celles qui concernent la commune de Portes viennent avant, par exemple, celle concernant la porte du château d’Aubais, du fait d’un calcul de pertinence efficace.
Un moteur pour les archives et les archivistes
On a compris que d’importants efforts ont été faits en direction des publics finals qui doivent être les principaux utilisateurs du moteur.
Toutefois, Bach est un moteur de recherche pour les descriptions d’archives qui prend en compte les spécificités du domaine archivistique. Nous avons déjà évoqué les principales caractéristiques archivistiques de ce moteur. Nous allons les récapituler et les compléter.
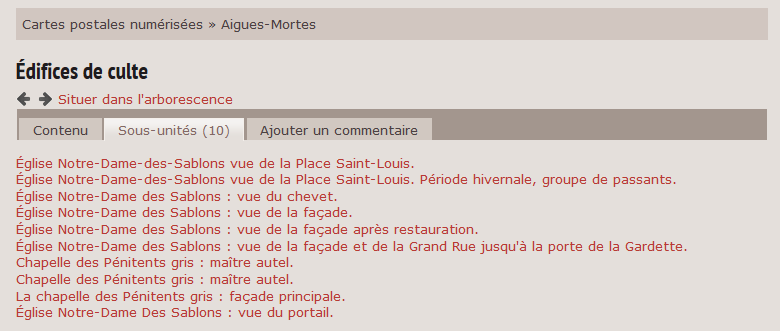
Les listes de réponses situent chaque occurrence dans son contexte hiérarchique, présenté en haut de la réponse.

Les réponses détaillées présentent également les niveaux parents et les niveaux enfants (quand ils existent) d’un niveau donné.
L’accès à l’instrument de recherche complet se fait aussi bien à partir de la liste que du détail des réponses.
Les facettes peuvent, bien entendu, être "archivistiques", comme dans l’exemple ci-dessous.
Le classement des réponses suivant l’ordre de l’inventaire. Les réponses à une requête sont alors classées suivant l’ordre dans lequel les descriptions se trouvent dans l’instrument de recherche.
La notion de niveau. Le terme sera peut-être à reprendre. Un instrument de recherche est généralement constitué d’une description de niveau haut (par exemple fonds), de descriptions de niveaux intermédiaires (par exemple groupes de documents) et de descriptions de niveau bas (par exemple dossiers ou pièces). Dans une liste de réponses, on peut avoir des descriptions correspondant à ces différents niveaux.
Dans l’exemple ci-dessous, la première description correspond à l’ensemble de l’instrument de recherche, la deuxième au premier titre de niveau 1, la troisième au premier titre de niveau 2, la quatrième au premier article.
On voit aussi que la facette niveau indique qu’il existe une description pour l’ensemble, 381 pour des groupes de documents et 2.817 pour les documents (ici, des pièces).
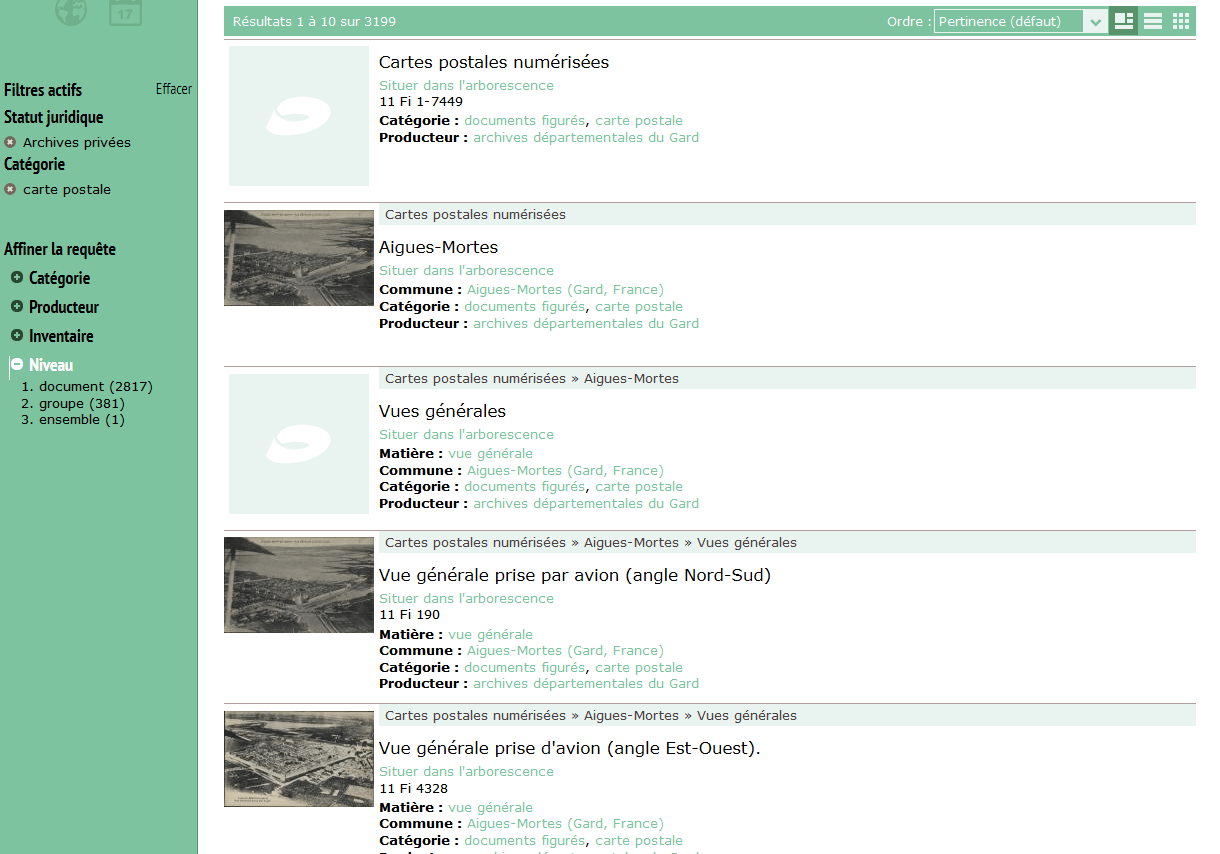
En filtrant sur "document", on n’a que les descriptions des pièces.

Les recherches nominatives
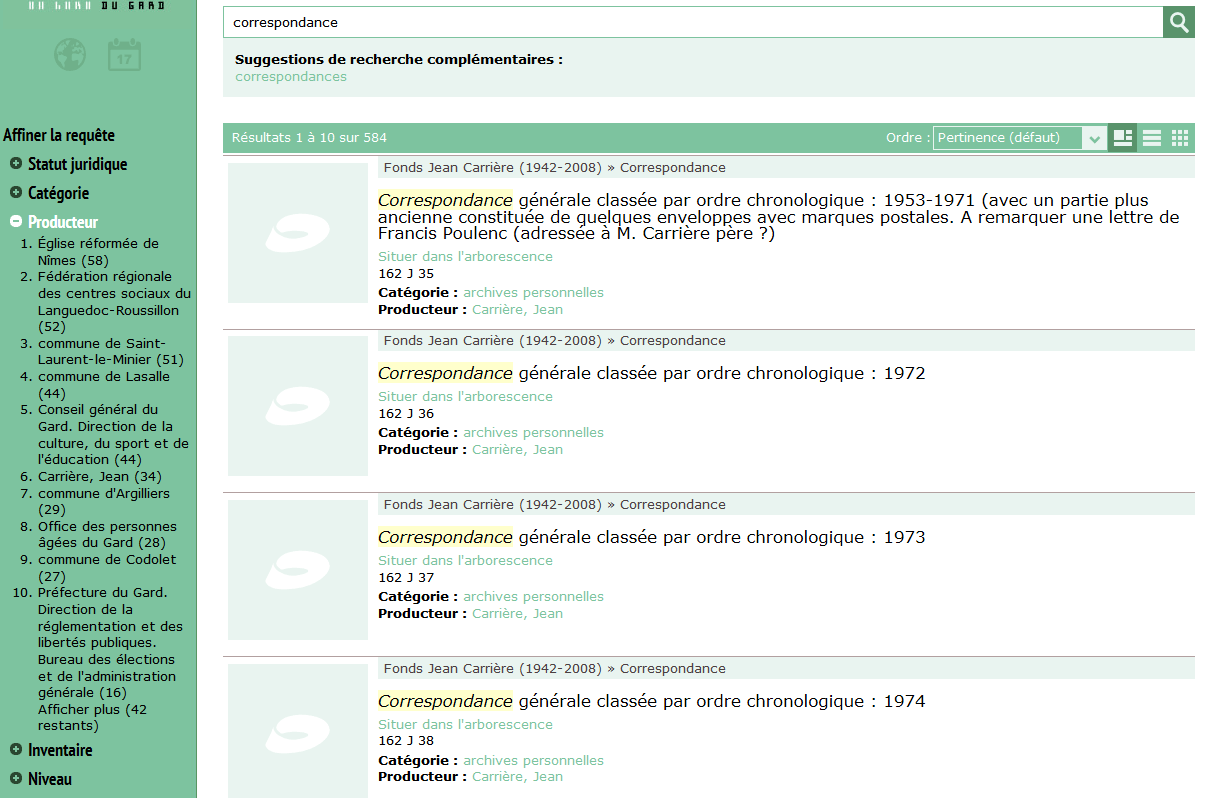
Bach a été conçu non seulement pour exploiter les instruments de recherche archivistiques conçus suivant la norme ISAD(G) et la DTD EAD, mais aussi pour les recherches dans des bases de données nominatives.
Un onglet permet de chercher dans les registres matricules militaires.
A. Principe de recherche
Le même principe de recherche simple par texte a été retenu, avec une zone unique de saisie. Si l’on saisit, par exemple, « jean bernard » qui sont tous les deux à la fois des prénoms et des noms très courants, on obtient de nombreuses réponses (5.082), mais celles qui contiennent à la fois Jean et Bernard comme nom et prénom viennent en premier.
Des facettes Nom, Prénom, Classe et Lieu de naissance permettent, si nécessaire, d’affiner les requêtes.
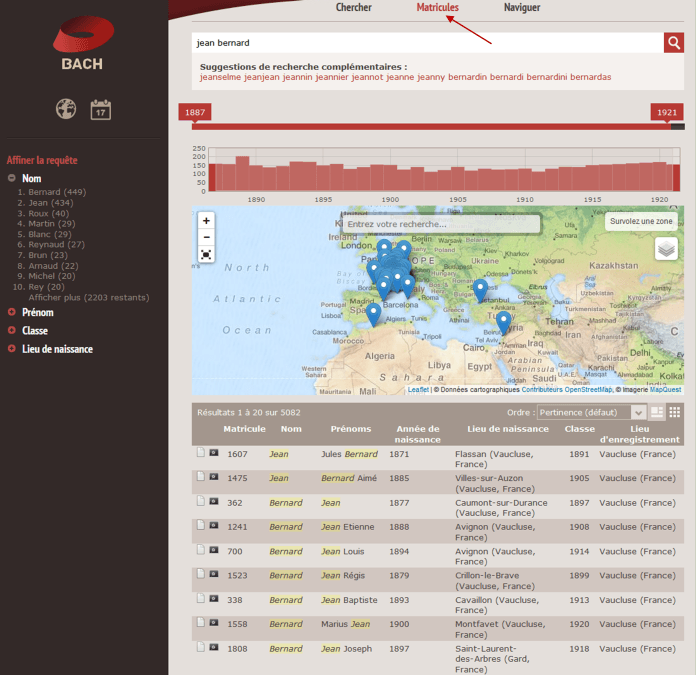
On peut, ici aussi, fonctionner en mode booléen en saisissant, par exemple « jean AND bernard ». Le nombre de réponses est effectivement plus réduit (25).
Notons que l’on peut aussi utiliser Bach pour faire des statistiques sur les occurrences de noms. En cherchant toutes les réponses, on obtient, dans cette base, 60.798 réponses. Grâce aux facettes, on voit d’emblée les 10 noms les plus fréquents.
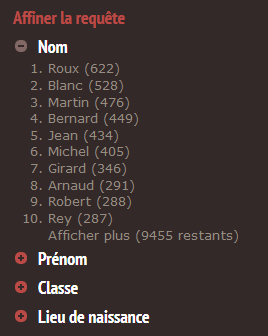
En cliquant sur « Afficher plus », on obtient l’ensemble des noms, par défaut dans l’ordre alphabétique et que l’on peut classez par occurrences.
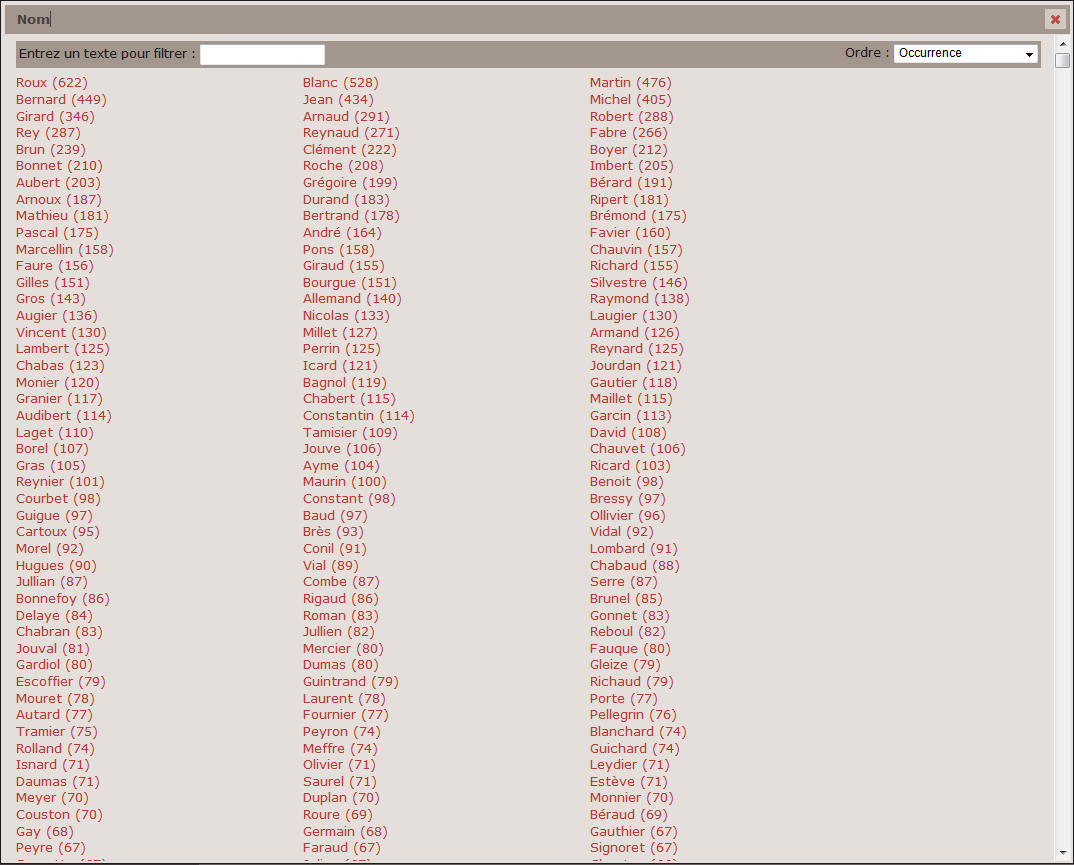
Une zone de recherche permet de filtrer sur un ou plus d’un nom

B. Affichage des résultats
Les résultats des recherches sont ici affichés sous la forme d’un simple tableau à colonnes.
La première colonne affiche une icône page qui permet d’ouvrir la description complète correspondant à la ligne.
La deuxième colonne, avec une icône appareil photo donne accès à la visionneuse d’images.
Ici encore, notre objectif a été de limiter le plus possible les clics nécessaires pour arriver à l’information recherchée.
Et maintenant ?
Après plus de deux années de travail, nous disposons maintenant d’une version bien élaborée de Bach. Plusieurs mises en ligne auraient déjà dû avoir lieu, Anaphore étant prête, mais les services commanditaires ont pris un peu de retard pour diverses raisons.
Bach et la visionneuse d’image qui l’accompagne sont des outils open source. Anaphore a prévu de mettre ces sources à disposition très bientôt.
Bien entendu, Bach continuera à évoluer grâce aux développements réalisés chez Anaphore et, peut-être, par d’autres.
Toutes vos remarques, critiques et suggestions seront les bienvenues.
Un petit site de présentation de Bach est disponible. Cette présentation donne accès à une application de démonstration avec seulement un instrument de recherche et une base de données « registres matricules ». Nous tenons à remercier les archives départementales du Gard et de Vaucluse pour nous avoir autorisés à monter certaines de leurs données qui ne sont pas encore officiellement diffusées.
Bach est le résultat de l’expérience et des réalisations accumulées par Anaphore au cours de plus de 20 ans au service des archives et des archivistes.
Bach, tel qu’il est aujourd’hui, a nécessité de nombreuses heures de conception, de développement, de tests, d’ajustements.
Le développement a été commencé par cinq élèves-ingénieurs de l’école Nancy Télécom (ex ESIAL) pendant l’année universitaire 2012-2013.
Johan Cwiklinski a repris le projet à partir d’avril 2013 et a réalisé une très grande partie des développements.
Vincent Fleurette et Sébastien Chaptal, jeunes développeurs, travaillent désormais également sur Bach.
Et, l’histoire continue...