
Une ontologie pour les archives pour quoi faire ?
L’idée de produire une ontologie pour la description archivistique est née d’un besoin. Donner d’abord à nos outils logiciels une orientation pertinente et à même d’anticiper des évolutions technologiques, qui, pour l’instant, semblent tarder à recevoir toute l’attention qu’elles méritent. Et, dans la même veine, participer activement à l’adoption des technologies du web des données dans les archives.
Tout comme, pour l’EAD en son temps, Anaphore avait su intégrer ce format dès 2001 puis lors de sa révision en 2002, participant ainsi activement à son adoption dans les services d’archives en France. Plus de dix ans plus tard, et à l’aune d’une évolution majeure de l’EAD, annoncée mais sans cesse repoussée, le pari tenu du web des données nous semble offrir un moment structurel clé pour l’évolution de nos pratiques.
Sans remettre en cause les fondements de notre métier, la prise en compte des technologies du web sémantique inscrira sans aucun doute la pratique archivistique dans le changement du paradigme numérique de ce début de 21e siècle.
Et ce n’est sans doute pas par hasard que des thématiques récurrentes du Conseil International des Archives et du Service interministériel des Archives de France (SIAF) annoncent depuis quelques années la nécessité de penser un modèle conceptuel pour les archives, mais aussi des travaux en cours allant dans cette directionClaire Sibille de Grimoüart, « Les normes de description et les formats apparentés » Journées d’études sur les formats EAD et EAC-CPF. Archives nationales d’outre-mer, 2 juin 2010.
Nils Brübach, Robert Nahuet et Claire Sibille de Grimoüart, « Une évolution dans les pratiques descriptives – vers un modèle conceptuel archivistique ? » dans Arbido, Norme und Standards. 14 juin 2012, pp. 4-9.
Conseil international des archives, sous-comité des normes de description, « Rapport d’étape pour la révision et l’harmonisation des normes de description de l’ICA », 4 juillet 2012.. Prenant ainsi acte du train déjà en marche pour les autres métiers cousins du patrimoine : bibliothèque, documentation, musées. Chez les premiers, par exemple, la mise en pratique des modèles FRBR et FRAD sonne l’heure d’un nouveau saut normatif.
Le web des données
Encore relativement méconnues, les technologies du web des données ou données liées (linked data), présentent l’immense perspective de la mise en commun, du partage et de la valorisation des métadonnées descriptives dans l’ADN même du Web.
Dit simplement, les données liées renvoient au fait d’utiliser le Web pour créer des relations entre des données de sources différentes, qu'il s'agisse de leur provenance, leur localisation géographique, ou, tout simplement, de systèmes hétérogènes qui, au sein d’une même institution, ne sont pas facilement interopérables.
D’un point de vue technique, il s’agit de données publiées dans le Web, lisibles par des machines, leur sens étant explicitement défini, liées à des sources externes, qui peuvent, à leur tour, être découvertes et atteintes par encore d’autres sources.
La force et l’intérêt des données liéesC’est en 2006 que Tim Berners-Lee, principal inventeur du Web, énonça les quatre règles pour publier des donnés sur le Web, règles universellement connues comme les principes des données liées (Linked data principles). http://www.w3.org/DesignIssues/LinkedData.html est la capacité de cette technologie d’identifier et de typer les relations entre les entités en utilisant les standards du Web, favorables à la lecture par les machines et permettant de révéler ainsi des interconnections qu’il serait impossible de produire par la seule intervention humaine.
Les standards du Web sont donc à la source même de cette technologie et, en conséquence, indissociables de sa mise en œuvre.
Des standards du Web
Le concept des données liées repose sur deux technologies fondamentales du Web : les URIs, (Universal Resource Identifier ou identifiant uniforme de ressource), et le protocole HTTP (HyperText Transfert Protocol). Les URLs (Uniform Resource Locators), que nous connaissons bien, sont des adresses de documents et autres entités que l’on peut trouver sur le Web. A contrario, les URIs sont un moyen générique d’identifier n’importe quelle entité existant dans le monde.
Les URIs et le protocole HTTP sont complétés par une autre technologie critique au Web des données, le RDF (Resource Description Framework).
Dans le Web des documents, le HTML (HyperText Markup Language), qui nous est plus familier, construit la structure et les relations entre les documents par des liens hypertextes non typés. Le RDF, pour sa part, fournit un modèle de données générique qui se présente sous forme de graphe, permettant ainsi de structurer et de typer les relations entre des ressources décrivant des choses existant dans le monde.
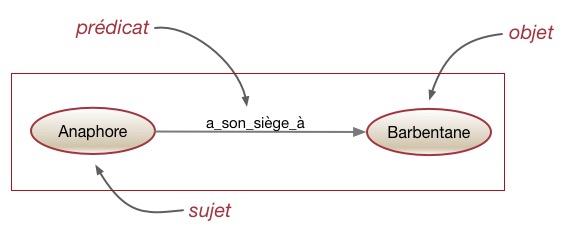
Le RDF est un modèle de données basé sur des triplets. Un triplet exprime un fait et est constitué de trois parties distinctes : sujet, prédicat, objet.
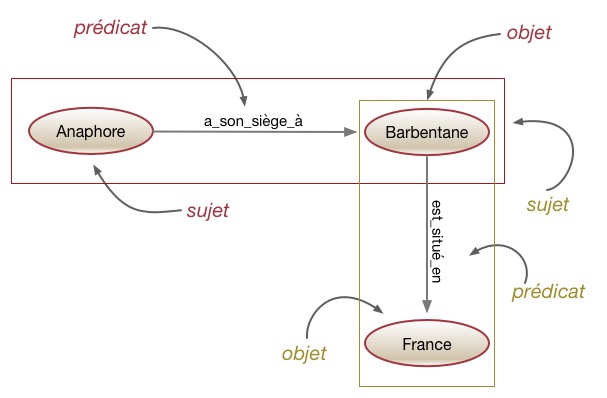
Le sujet d’un triplet est l’URI identifiant la ressource décrite. L’objet peut être une simple valeur littérale, chaîne de caractères, nombre, date ou, alors, l’URI d’une autre ressource, elle-même en relation avec le sujet. Le prédicat, situé entre les deux, indique le type de relation existant entre le sujet et l’objet. Le prédicat est lui aussi représenté par une URI. Les URIs des prédicats sont issues de vocabulaires, c’est-à-dire, des collections d’URIs utilisées pour représenter l’information d’un domaine.
L’intérêt le plus immédiat d’utiliser le modèle RDF dans le contexte des technologies du web des données est qu’en ayant recours à des URIs comme identifiants uniques pour nommer toute chose et se référer à tout vocabulaire, ce modèle propose de façon intrinsèque une utilisation à l’échelle globale du Web et permet à toute personne de se référer à toute chose.
Le RDF étant un modèle de données et non un format, publier un graphe RDF sur le Web nécessite l’utilisation d’une syntaxe dite de sérialisation RDF. Il existe plusieurs formats de sérialisation standardisés par le W3C comme RDF/XML, Turtle, N-Triples, RDF/JSON, RDFa.
Une ontologie pour modèle conceptuel
Pour reprendre la définition de Thomas R. Gruberhttp://fr.wikipedia.org/wiki/Ontologie_(informatique) ; http://tomgruber.org/writing/ontology-definition-2007.htm qui fait autorité : « Une ontologie est la spécification d'une conceptualisation. [...] Une conceptualisation est une vue abstraite et simplifiée du monde que l'on veut représenter. »
Si les vocabulaires représentent l’information d’un domaine, une ontologie est une manière de représenter un domaine par la description formelle des entités ou objets du domaine et des relations entre ces entités. Le résultat de cette formalisation descriptive entité/relation, s'appelle un modèle conceptuel.

Quel intérêt pour les archives ?
Les technologies des données liées offrent la possibilité d’intégrer les métadonnées descriptives des archives dans la fabrique même du Web.
Faire de nos métadonnées descriptives des données liées, c’est rendre visible, lisible et exploitable le contenu de nos archives par les machines et par les humains à l’échelle du Web. Réciproquement, les données liées offrent aux archivistes des moyens sans commune mesure d’enrichir leurs contenus par l’apport de données externes publiées par d’autres fournisseurs du Web.
Pour reformuler la question initialement posée, pourquoi une ontologie par Anaphore pour la description archivistique ? Pour ouvrir aux métadonnées descriptives des archives le chemin des technologies des données liées, métadonnées que nous contribuons à produire par nos outils et par notre connaissance du domaine. Il ne s’agit pas, loin s’en faut, de produire l'ontologie définitive pour les archives (car ne perdons pas de vue qu’une ontologie n’est rien d’autre qu’une vue particulière du monde que l’on cherche à formaliser), mais bien d’offrir une réponse pragmatique à une problématique technique que nous considérons comme essentielle pour l’avenir de nos métiers et par extension du nôtre.
À suivre…
Rétroliens/Pingbacks